
<强>方法:使用urlencode函数
urllib.request.urlopen ()
开发者工具浏览器按F12或者右键按检查,有个抓包工具网络,刷新页面,可以看到网页资源,可以看到请求头信息,UA 在抓包工具点击任意请求,可以看到所有请求信息,向应信息, 主要用到标题,响应,响应头存放响应头信息,请求头存放请求信息 反爬出机制:网站会检查请求的UA,如果发现UA是爬虫程序,会拒绝提供网站页面数据。 如果网站检查发现请求UA是基于某一款浏览器标识(浏览器发起的请求),网站会认为请求是正常请求,会把页面数据响应信息给客户端 用户代理(UA):请求载体的身份标识 <强>反反爬虫机制: 伪造爬虫程序的请求的UA,把爬虫程序的请求UA伪造成谷歌标识,火狐标识 <强>通过自定义请求对象,用于伪装爬虫程序请求的身份。 user - agent参数,简称为UA,该参数的作用是用于表明本次请求载体的身份标识。如果我们通过浏览器发起的请求,则该请求的载体为当前浏览器,则UA参数的值表明的是当前浏览器的身份标识表示的一串数据。 如果我们使用爬虫程序发起的一个请求,则该请求的载体为爬虫程序,那么该请求的UA为爬虫程序的身份标识表示的一串数据。 有些网站会通过辨别请求的UA来判别该请求的载体是否为爬虫程序,如果为爬虫程序,则不会给该请求返回响应,那么我们的爬虫程序则也无法通过请求爬取到该网站中的数据值,这也是反爬虫的一种初级技术手段。那么为了防止该问题的出现,则我们可以给爬虫程序的UA进行伪装,伪装成某款浏览器的身份标识。 上述案例中,我们是通过请求模块中的urlopen发起的请求,该请求对象为urllib中内置的默认请求对象,我们无法对其进行UA进行更改操作.urllib还为我们提供了一种自定义请求对象的方式,我们可以通过自定义请求对象的方式,给该请求对象中的UA进行伪装(更改)操作。 <>强自定义请求头信息字典可以添加谷歌浏览器的UA标识,自定义请求对象来伪装成谷歌UA 1。封装自定义的请求头信息的字典, 2。注意:在头字典中可以封装任意的请求头信息 3。将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,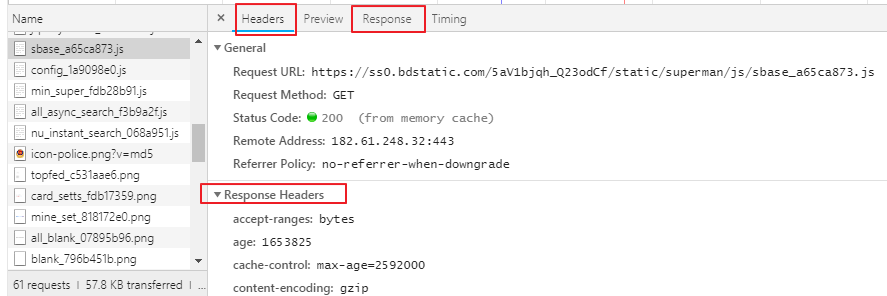
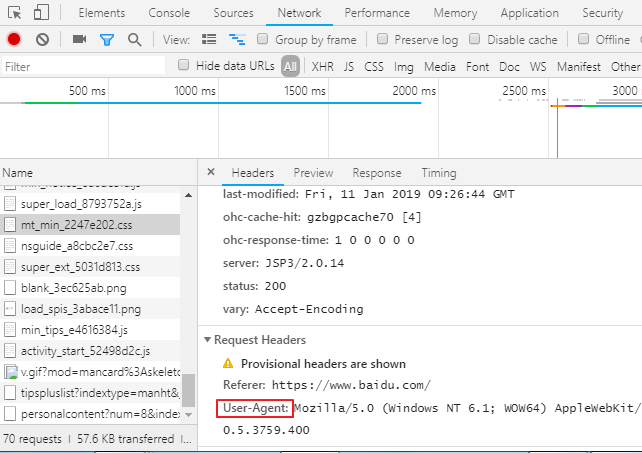
从中获取UA的值python爬虫urllib模块反爬虫机制UA详解




