Hadoop是基于Java的,所以首先需要安装配置好Java环境。从官网下载JDK,我用的是1.8版本。在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中。
danieldu@daniels——macbook pro - 857 ~/下载scp jdk-8u121-linux-x64.tar。广州root@hadoop100:/opt/软件
root@hadoop100的密码:
danieldu@daniels——macbook pro - 857 ~/下载
其实我在Mac上装了一个神器-叉车。可以通过SFTP的方式连接到远程linux。然后在操作本地电脑一样,直接把文件拖过去就行了。而且好像配置文件的编辑,也可以不用在linux下用vi,直接在Mac下用崇高的远程打开就可以编辑了:)
然后在linux虚拟机中(ssh登录上去)解压缩到/opt/模块目录下
[root@hadoop100包括]#焦油-zxvf/opt/软件/jdk-8u121-linux-x64.tar。广州- c/opt/模块/
然后需要设置一下环境变量,打开/etc/profile,添加JAVA_HOME并设置路径用vi打开也行,或者如果你也安装了类似叉车这样的可以远程编辑文件的工具那更方便。
<代码> vi/etc/profile
按shift + G跳到文件最后,按我切换到编辑模式,添加下面的内容,主要路径要搞对。
# JAVA_HOME
出口JAVA_HOME=/opt/模块/jdk1.8.0_121
导出路径=$路径:$ JAVA_HOME/bin
按ESC,然后:wq存盘退出。
执行下面的语句使更改生效
[root@hadoop100包括]#源/etc/profile
检查java是否安装成功。如果能看到版本信息就说明安装成功了。
[root@hadoop100包括]# java - version
java版本“1.8.0_121”
Java (TM) SE运行时环境(构建1.8.0_121-b13)
Java HotSpot VM (TM) 64位服务器(构建25.121十三区最,混合模式)
[root@hadoop100包括]#
Hadoop的安装也是只需要把Hadoop的tar包拷贝到linux,解压,设置环境变量。然后用之前做好的xsync脚本,把更新同步到集群中的其他机器。如果你不知道xcall, xsync怎么写的。可以翻一下之前的文章。这样集群里的所有机器就都设置好了。
[root@hadoop100包括]#焦油-zxvf/opt/软件/hadoop-2.7.3.tar。广州- c/opt/模块/[root@hadoop100包括]# vi/etc/profile继续添加HADOOP_HOME
# JAVA_HOME
出口JAVA_HOME=/opt/模块/jdk1.8.0_121
导出路径=$路径:$ JAVA_HOME/bin
# HADOOP_HOME
出口HADOOP_HOME=/opt/模块/hadoop-2.7.3
导出路径=$路径:$ HADOOP_HOME/bin: $ HADOOP_HOME/sbin
[root@hadoop100包括]#源/etc/profile
把更改同步到集群中的其他机器
[root@hadoop100包括]# xsync/etc/profile
[root@hadoop100包括]# xcall源/etc/profile
[root@hadoop100包括]# xsync hadoop-2.7.3/
然后需要对Hadoop集群环境进行配置。对于集群的资源配置是这样安排的,当然hadoop100显得任务重了一点:)
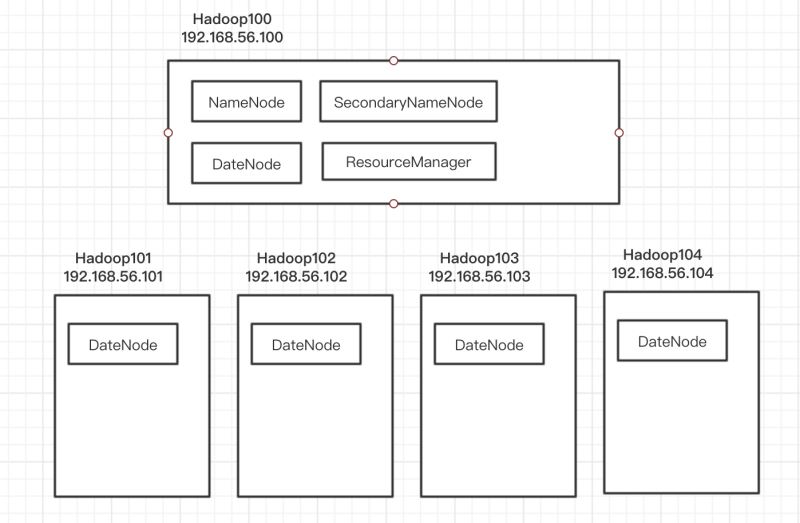
编辑0/opt/模块/hadoop-2.7.3/etc/hadoop/mapred-env.sh yarn-env.sh hadoop-env。上海这几个壳文件中的JAVA_HOME,设置为真实的绝对路径。
<代码> export JAVA_HOME=/opt/模块/jdk1.8.0_121
打开编辑/opt/模块/hadoop-2.7.3/etc/hadoop/核心位点。xml,内容如下
& lt; configuration>
& lt; property>
& lt; name> fs.defaultFS
& lt; value> hdfs://hadoop100:9000
& lt;/property>
& lt; property>
& lt; name> hadoop.tmp.dir
& lt; value>/opt/模块/hadoop-2.7.3/数据/tmp
& lt;/property>
& lt;/配置
编辑<代码>/opt/模块/hadoop-2.7.3/etc/hadoop/hdfs-site。xml>
& lt; configuration>
& lt; property>
& lt; name> dfs.replication





