,,,,,,,决策树也是有监督机器学习方法。电影《无耻混蛋》里有一幕游戏,在德军小酒馆里有几个人在玩20问题游戏,游戏规则是一个设迷者在纸牌中抽出一个目标(可以是人,也可以是物),而猜谜者可以提问题,设迷者只能回答是或者不是,在几个问题(最多二十个问题)之后,猜谜者通过逐步缩小范围就准确的找到了答案。这就类似于决策树的工作原理。(图一)是一个判断邮件类别的工作方式,可以看出判别方法很简单,基本都是阈值判断,关键是如何构建决策树,也就是如何训练一个决策树。

(图一)
构建决策树的伪代码如下:
检查每一项数据集是否在同一个类:
如果是返回的类标签
其他的
找到最好的功能将数据
将数据集
创建一个分支节点
对于每一个分裂
调用创建分支,并将结果添加到分支节点
返回分支节点
之前
,,,,,原则只有一个,尽量使得每个节点的样本标签尽可能少,注意上面伪代码中一句说:找到最好的功能分割数据,那么如何找到最好的特性# 63;一般有个准则就是尽量使得分支之后节点的类别纯一些,也就是分的准确一些。如(图二)中所示,从海洋中捞取的5个动物,我们要判断他们是否是鱼,先用哪个特征?

(图二)
,,,,,为了提高识别精度,我们是先用“离开陆地能否存活”还是“是否有蹼”来判断?我们必须要有一个衡量准则,常用的有信息论,基尼纯度等,这里使用前者。我们的目标就是选择使得分割后数据集的标签信息增益最大的那个特征,信息增益就是原始数据集标签基熵减去分割后的数据集标签熵,换句话说,信息增益大就是熵变小,使得数据集更有序。熵的计算如(公式一)所示:
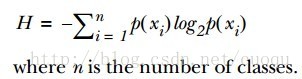
有了指导原则,那就进入代码实战阶段,先来看看熵的计算代码:
def calcShannonEnt(数据):
numEntries=len(数据集)
labelCounts={}
featVec的数据集:#独特元素的数量和他们的病症
currentLabel=featVec [1]
如果currentLabel不在labelCounts.keys (): labelCounts [currentLabel]=0
labelCounts [currentLabel] +=1 #收集所有类别的数目,创建字典
shannonEnt=0.0
在labelCounts关键:
概率=浮动(labelCounts[主要])/numEntries
shannonEnt -=概率*日志(概率,2)# log 2计算熵
返回shannonEnt
之前
有了熵的计算代码,接下来看依照信息增益变大的原则选择特征的代码:
def splitDataSet(数据集、轴、价值):
retDataSet=[]
featVec的数据集:
如果featVec(轴)==值:
reducedFeatVec=featVec(轴):#切轴用于分裂
reducedFeatVec.extend (featVec[轴+ 1:])
retDataSet.append (reducedFeatVec)
返回retDataSet
def chooseBestFeatureToSplit(数据):
numFeatures=len(数据集[0])——1 #最后一列用于标签
baseEntropy=calcShannonEnt(数据集)
bestInfoGain=0.0;bestFeature=1
因为我在范围(numFeatures): #遍历的所有特性
featList=[例子[我]例如在数据集]#创建一个列表的所有该特性的例子
uniqueVals=组(featList) #一组独特的价值观
newEntropy=0.0
uniqueVals价值:
subDataSet=splitDataSet(数据集,我,值)
概率=len (subDataSet)/浮动(len(数据集)
newEntropy +=概率* calcShannonEnt (subDataSet)
infoGain=baseEntropy - newEntropy #计算信息增益;即减少熵
如果(infoGain比;bestInfoGain): #比较这个迄今为止最好的获取#选择信息增益最大的代码在此
bestInfoGain=infoGain #如果比目前最好的,最好的
bestFeature=我
返回bestFeature #返回一个整数
之前
,,,,,,,从最后一个如果可以看的出,选择使得信息增益最大的特征作为分割特征,现在有了特征分割准则,继续进入一下个环节,如何构建决策树,其实就是依照最上面的伪代码写下去,采用递归的思想依次分割下去,直到执行完成就构建了决策树。代码如下:
def majorityCnt(班级名册):
classCount={}
在班级名册投票:
如果投票不在classCount.keys (): classCount(投票)=0
classCount【投票】+=1
sortedClassCount=排序(classCount.iteritems()、关键=operator.itemgetter(1)反向=True)
返回sortedClassCount [0] [0]
def createTree(数据集、标签):
班级名册=(例子[1]例如数据集)
如果classList.count(班级名册[0])==len(班级名册):
返回班级名册[0]#停止分裂,当所有的类都是平等的
如果len(数据集[0])==1:#停止分裂,当数据集没有更多的功能
返回majorityCnt(班级名册)
bestFeat=chooseBestFeatureToSplit(数据集)
bestFeatLabel=标签(bestFeat)
myTree={bestFeatLabel: {}}
德尔(标签(bestFeat))
featValues=[示例(bestFeat)例如在数据集)
uniqueVals=集(featValues)
uniqueVals价值:
subLabels=[:] #标签复制所有的标签,所以树木不打乱现有的标签
myTree [bestFeatLabel][]价值=createTree (splitDataSet(数据集,bestFeat、价值),subLabels)
返回myTree





