我用的是Anaconda3,用世爵编写pytorch的代码,在Anaconda3中新建了一个pytorch的虚拟环境(虚拟环境的名字就叫pytorch)。
<强>以下内容仅供参考哦~ ~
1。首先打开蟒蛇提示,然后输入激活pytorch,进入pytorch。
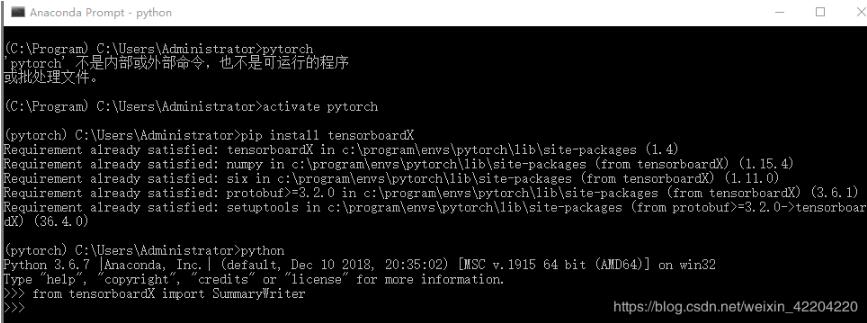
2。输入pip安装tensorboardX,安装完成后,输入python,用从tensorboardX进口SummaryWriter检验是否安装成功。如下图所示:
3。安装完成之后,先给大家看一下我的文件夹,如下图:
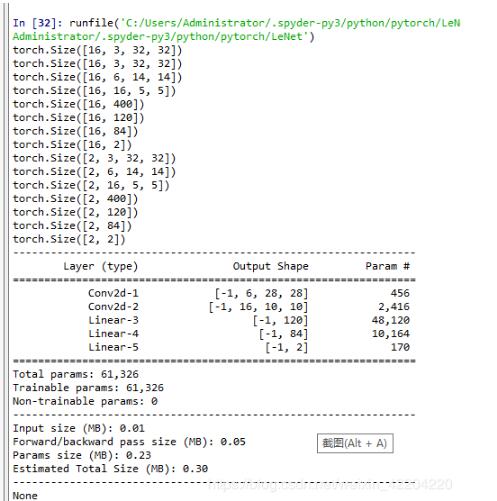
假设用LeNet5框架识别图像的准确率,LeNet.py代码如下:
示网络结构如下图:
训练代码(LeNet_train_test.py)如下:
样本图像是pytorch官网中介绍迁移学习时用到的,蚂蚁与蜜蜂的二分类图像,图像大小不一.LeNet5的输入图像是32 * 32,所以进行分类时会损失一定的图像像素,导致识别率较低。
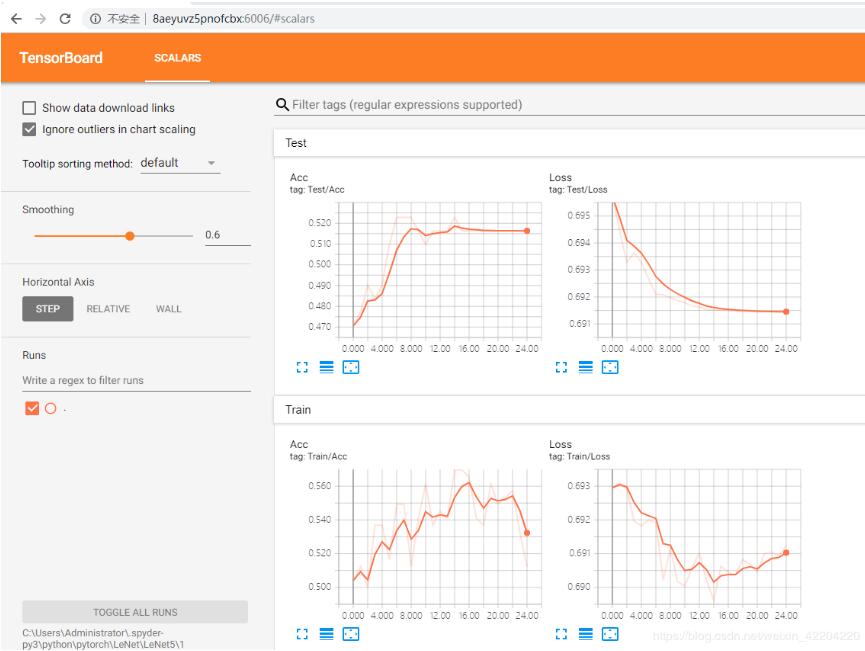
下面介绍显示损失和acc曲线,在以上训练代码中,作家=SummaryWriter (LeNet5)表示在训练过程中会生成LeNet5文件夹,保存损失曲线和acc曲线的文件,如下图:
首先解释一下这个文件夹为什么是1,因为我之前训练了很多次,在LeNet5文件夹下有很多1文件夹中这样的文件,待会用蟒蛇提示来显示损失和acc的时候,它只识别一个文件,所以我就重新建了一个1文件夹,并将刚刚运行完毕的文件放到文件夹中。在LeNet_train_test。py中,作家。add_scalar(火车/损失,epoch_loss时代)和
writer.add_scalar(火车/Acc, epoch_acc时代),这两行代码就是生成的列车数据集的损失和Acc曲线,同理测试数据集亦是如此。
好啦,下面开始显示损失和acc:
1。打开蟒蛇提示,再次进入pytorch虚拟环境,
2。输入tensorboard logdir=,红色部分是来自上图文件夹的根目录,按回车键,会出现tensorboard的版本和一个网址,总体显示效果如下图:

复制网址到浏览器中,在此处是复制:http://8AEYUVZ5PNOFCBX: 6006到浏览器中,

最终结果如下图: