中文分词≠自然语言处理!
<强> Hanlp
HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用.HanLP具备功能完善,性能高效、架构清晰,语料时新,可自定义的特点。
功能:中文分词词性标注命名实体识别依存句法分析关键词提取新词发现短语提取自动摘要文本分类拼音简繁
中文分词只是第一步;HanLP从中文分词开始,覆盖词性标注,命名实体识别,句法分析,文本分类等常用任务,提供了丰富的API。
不同于一些简陋的分词类库,HanLP精心优化了内部数据结构和IO接口,做到了毫秒级的冷启动,千万字符每秒的处理速度,而内存最低仅需120 mb。无论是移动设备还是大型集群,都能获得良好的体验。
不同于市面上的商业工具,HanLP提供训练模块,可以在用户的语料上训练模型并替换默认模型,以适应不同的领域。项目主页上提供了详细的文档,以及在一些开源语料上训练的模型。
HanLP希望兼顾学术界的精准与工业界的效率,在两者之间取一个平衡,真正将自然语言处理普及到生产环境中去。
我们使用的pyhanlp是用python包装了HanLp的java接口。
<强> 2.1 python下安装pyhanlp
pip安装
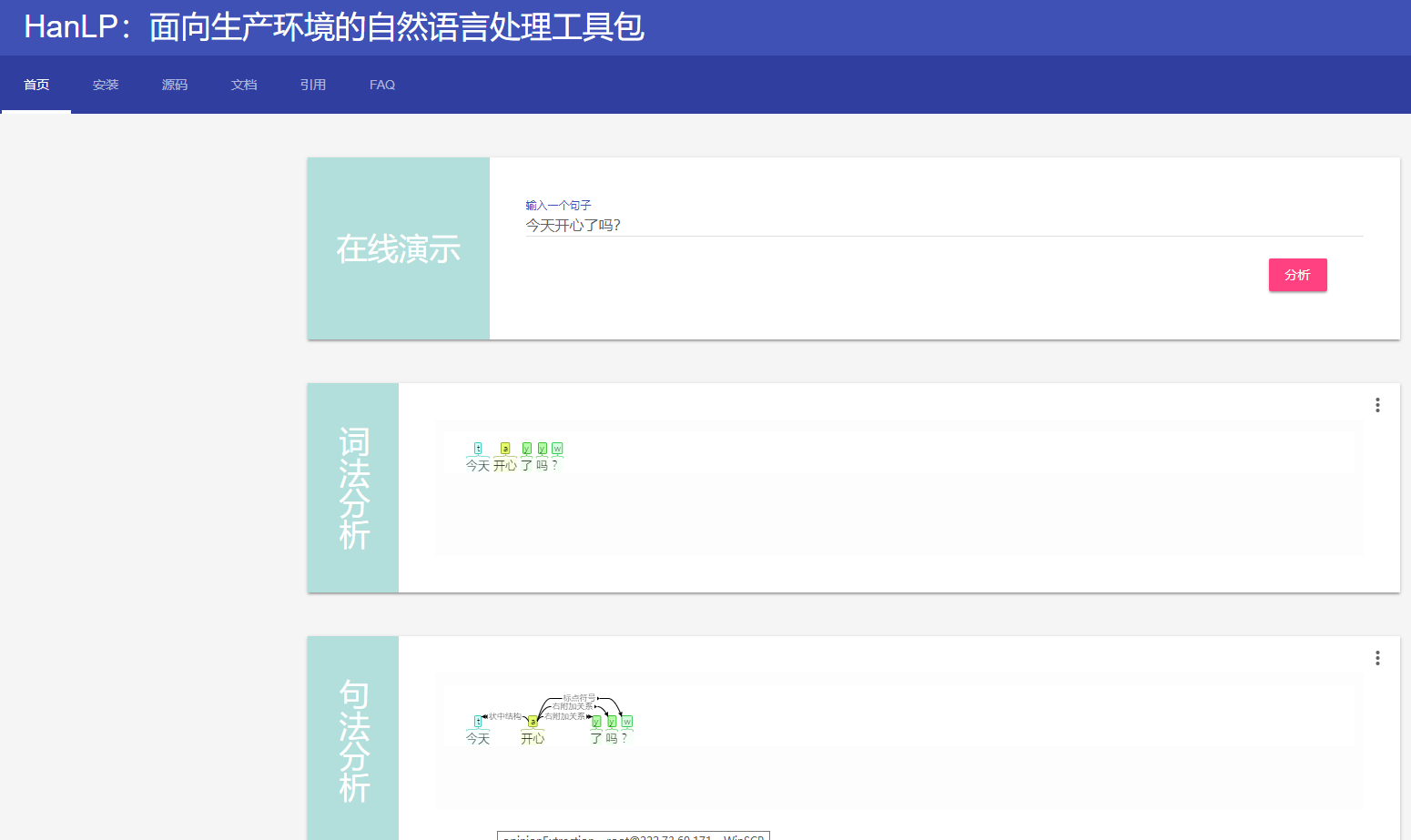
第一次进口pyhanlp会下载一个比较大的数据集,需要耐心等待下,后面再进口就不会有了。 详情请见pyhanlp官方文档 <强> 2.2 pyhanlp简单使用方法 分词使用 依存分析使用 <强> 2.3 pyhanlp可视化 如果大家看不太清楚上面的输出,pyhanlp提供了一个很好的展示交付界面,只要一句命令就能启动一个web服务 登录http://localhost: 8765就能看下可视化界面,能看到分词结果和依存关系的结果,是不是很直观。这个网页上还有安装说明,源码链接,文档链接,常见的问题(FAQ)。