
本文实例讲述了java数据结构与算法之桶排序实现方法。分享给大家供大家参考,具体如下:
假定输入是由一个随机过程产生的[0,M)区间上均匀分布的实数。将区间[0,M)划分为n个大小相等的子区间(桶),将n个输入元素分配到这些桶中,对桶中元素进行排序,然后依次连接桶输入0≤(1 . .n] & lt; M辅助数组B (0 . . n - 1)是一指针数组,指向桶(链表)。将n个记录分布到各个桶中去。如果有多于一个记录分到同一个桶中,需要进行桶内排序。最后依次把各个桶中的记录列出来记得到有序序列。
bindex=f(关键),,其中,bindex为桶数B组的下标(即第bindex个桶),k为待排序列的关键字。桶排序之所以能够高效,其关键在于这个映射函数,它必须做到:很显,然,我们下面举个例子:
假如待排序列K={49岁,38岁,35岁,97年,76年,73年,27岁的49}。这些数据全部在1 - 100之间,因此我们定制10个桶,然后确定映射函数f (K)=K/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:
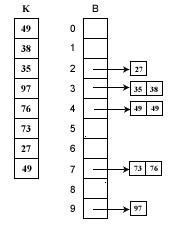
对上图只要顺序输出每个B[我]中的数据就可以得到有序序列了。
<强>算法核心代码如下:
<强>桶排序代价分析
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f (k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶),然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O (N * logN)了)。因此,我们需要尽量做到下面两点:
对于N个待排数据,M个桶,平均每个桶(N/M)个数据的桶排序平均时间复杂度为:
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O (N)。
<强>总结:
即以下三点:
<>强补充:在查找算法中,基于比较的查找算法最好的时间复杂度也是O (logN)。比如折半查找,平衡二叉树,红黑树等。但是哈希表却有O (C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。那么:哈希表的思想和桶排序是不是有一曲同工之妙呢& # 63;
实际上,桶排序对数据的条件有特殊要求,如果数组很大的话,那么分配几亿个桶显然是不可能的,所以桶排序有其局限性,适合元素值集合并不大的情况。
更多关于java算法相关内容感兴趣的读者可查看本站专题:《java数据结构与算法教程》、《java操作DOM节点技巧总结》,《java文件与目录操作技巧汇总》和《java缓存操作技巧汇总》
希望本文所述对大家java程序设计有所帮助。




