
这几天caffe2发布了,支持移动端,我理解是类似单片机的物联网吧应该不是手机之类的,试想iphone7跑CNN,画面太美~
作为一个刚入坑的,甚至还没入坑的人,咱们还是老实研究下tensorflow吧,虽然它没有咖啡好上手.tensorflow的特点我就不介绍了:
-
<李>基于Python,写的很快并且具有可读性。
<李>支持CPU和GPU,在多GPU系统上的运行更为顺畅。
<李>代码编译效率较高。
<李>社区发展的非常迅速并且活跃。
<李>能够生成显示网络拓扑结构和性能的可视化图。
tensorflow的运行流程主要有2步,分别是构造模型和训练。
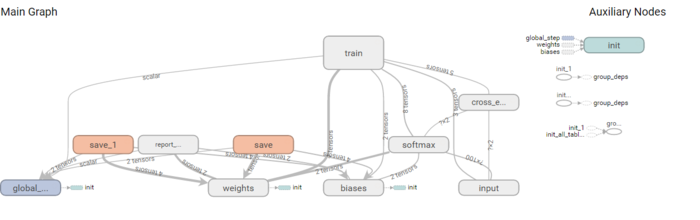
在构造模型阶段,我们需要构建一个图(图)来描述我们的模型,tensoflow的强大之处也在这了,支持tensorboard:
 # - * -编码:utf - 8 - *
熊猫作为pd导入
进口numpy np
进口tensorflow特遣部队
从进口计数器集合
从sklearn。数据导入fetch_20newsgroups
def get_word_2_index(词汇):
word2index={}
对于我,在列举(词汇):
word2index[词]=我
返回word2index
batch_size def get_batch (df):
批次=[]
结果=[]
文本=df。数据(我* * batch_size: batch_size + batch_size]
类别=df。目标(我* * batch_size: batch_size + batch_size]
文本的文本:
层=np.zeros (total_words dtype=浮动)
词的文本。分割(' '):
层[word2index [word.lower ()]] +=1
batches.append(层)
类别的类别:
y=np.zeros ((3), dtype=浮动)
如果类别==0:
y [0]=1。
elif类别==1:
y [1]=1。
其他:
y [2]=1。
results.append (y)
返回np.array(批次)、np.array(结果)
def multilayer_perceptron (input_tensor、重量偏差):
#隐藏层RELU函数激励
layer_1_multiplication=特遣部队。matmul (input_tensor、重量(h2的))
layer_1_addition=特遣部队。添加(layer_1_multiplication偏见[' b1 '])
layer_1=tf.nn.relu (layer_1_addition)
layer_2_multiplication=特遣部队。matmul (layer_1、重量(h3的))
layer_2_addition=特遣部队。add (layer_2_multiplication偏见(b2的))
layer_2=tf.nn.relu (layer_2_addition)
#输出层
out_layer_multiplication=特遣部队。matmul (layer_2权重['从'])
out_layer_addition=out_layer_multiplication +偏见(出来的)
返回out_layer_addition
#主要
#从sklearn.datas获取数据
凯特=[“comp.graphics”、“sci.space”,“rec.sport.baseball”)
newsgroups_train=fetch_20newsgroups(=盎鸪怠?子集分类=美食)='测试' newsgroups_test=fetch_20newsgroups(子集,类别=美食)
#计算训练和测试数据总数
词汇=计数器()
在newsgroups_train.data文本:
词的文本。分割(' '):
词汇(word.lower ()] +=1
在newsgroups_test.data文本:
词的文本。分割(' '):
词汇(word.lower ()] +=1
total_words=len(词汇)
word2index=get_word_2_index(词汇)
n_hidden_1=100 #一层隐藏层神经元个数
n_hidden_2=100 #二层隐藏层神经元个数
n_input=total_words
n_classes=3 #图形、科学。空间和棒球3层输出层即将文本分为三类
#占位
input_tensor=tf.placeholder (tf。float32,没有,n_input, name="输入")
output_tensor=tf.placeholder (tf。float32,(没有,n_classes)、名称=笆涑觥?
#正态分布存储权值和偏差值
重量={
“氢气”:tf.Variable (tf。random_normal ([n_input n_hidden_1])),
“h3”: tf.Variable (tf。random_normal ([n_hidden_1 n_hidden_2])),
“出”:tf.Variable (tf。random_normal ([n_hidden_2 n_classes]))
}
偏见={
“b1”: tf.Variable (tf.random_normal ([n_hidden_1])),
“b2”: tf.Variable (tf.random_normal ([n_hidden_2])),
“出”:tf.Variable (tf.random_normal ([n_classes]))
}
#初始化
预测=multilayer_perceptron (input_tensor、重量偏差)
#定义损失和优化器采用softmax函数
# reduce_mean计算平均误差=tf.reduce_mean (tf.nn损失。softmax_cross_entropy_with_logits(分对数=预测,标签=output_tensor))
优化器=tf.train.AdamOptimizer (learning_rate=learning_rate) .minimize(损失)
#初始化所有变量
init=tf.global_variables_initializer ()
#部署图
与tf.Session税():
sess.run (init)
training_epochs=100
display_step=5
batch_size=1000
#培训
时代的范围(training_epochs):
avg_cost=0。
total_batch=int (len (newsgroups_train.data)/batch_size)
因为我在范围(total_batch):
batch_x batch_y=get_batch (newsgroups_train,我,batch_size)
c, _=sess.run(损失,优化器,feed_dict={input_tensor: batch_x output_tensor: batch_y})
#计算平均损失
avg_cost +=c/total_batch
#每5次时代展示一次损失
如果时代% display_step==0:
打印(“时代:“,‘% d %(+ 1)时代,“损失=?“{:.6f}”.format (avg_cost))
打印(“结束了!”)
#测试模型
correct_prediction=tf.equal (tf。argmax(预测,1),特遣部队。argmax (output_tensor 1))
#计算准确率
精度=tf.reduce_mean (tf。铸造(correct_prediction“浮动”))
total_test_data=https://www.yisu.com/zixun/len (newsgroups_test.target)
batch_x_test batch_y_test=get_batch (newsgroups_test 0 total_test_data)
打印(“精度:精度。eval ({input_tensor: batch_x_test output_tensor: batch_y_test}))
# - * -编码:utf - 8 - *
熊猫作为pd导入
进口numpy np
进口tensorflow特遣部队
从进口计数器集合
从sklearn。数据导入fetch_20newsgroups
def get_word_2_index(词汇):
word2index={}
对于我,在列举(词汇):
word2index[词]=我
返回word2index
batch_size def get_batch (df):
批次=[]
结果=[]
文本=df。数据(我* * batch_size: batch_size + batch_size]
类别=df。目标(我* * batch_size: batch_size + batch_size]
文本的文本:
层=np.zeros (total_words dtype=浮动)
词的文本。分割(' '):
层[word2index [word.lower ()]] +=1
batches.append(层)
类别的类别:
y=np.zeros ((3), dtype=浮动)
如果类别==0:
y [0]=1。
elif类别==1:
y [1]=1。
其他:
y [2]=1。
results.append (y)
返回np.array(批次)、np.array(结果)
def multilayer_perceptron (input_tensor、重量偏差):
#隐藏层RELU函数激励
layer_1_multiplication=特遣部队。matmul (input_tensor、重量(h2的))
layer_1_addition=特遣部队。添加(layer_1_multiplication偏见[' b1 '])
layer_1=tf.nn.relu (layer_1_addition)
layer_2_multiplication=特遣部队。matmul (layer_1、重量(h3的))
layer_2_addition=特遣部队。add (layer_2_multiplication偏见(b2的))
layer_2=tf.nn.relu (layer_2_addition)
#输出层
out_layer_multiplication=特遣部队。matmul (layer_2权重['从'])
out_layer_addition=out_layer_multiplication +偏见(出来的)
返回out_layer_addition
#主要
#从sklearn.datas获取数据
凯特=[“comp.graphics”、“sci.space”,“rec.sport.baseball”)
newsgroups_train=fetch_20newsgroups(=盎鸪怠?子集分类=美食)='测试' newsgroups_test=fetch_20newsgroups(子集,类别=美食)
#计算训练和测试数据总数
词汇=计数器()
在newsgroups_train.data文本:
词的文本。分割(' '):
词汇(word.lower ()] +=1
在newsgroups_test.data文本:
词的文本。分割(' '):
词汇(word.lower ()] +=1
total_words=len(词汇)
word2index=get_word_2_index(词汇)
n_hidden_1=100 #一层隐藏层神经元个数
n_hidden_2=100 #二层隐藏层神经元个数
n_input=total_words
n_classes=3 #图形、科学。空间和棒球3层输出层即将文本分为三类
#占位
input_tensor=tf.placeholder (tf。float32,没有,n_input, name="输入")
output_tensor=tf.placeholder (tf。float32,(没有,n_classes)、名称=笆涑觥?
#正态分布存储权值和偏差值
重量={
“氢气”:tf.Variable (tf。random_normal ([n_input n_hidden_1])),
“h3”: tf.Variable (tf。random_normal ([n_hidden_1 n_hidden_2])),
“出”:tf.Variable (tf。random_normal ([n_hidden_2 n_classes]))
}
偏见={
“b1”: tf.Variable (tf.random_normal ([n_hidden_1])),
“b2”: tf.Variable (tf.random_normal ([n_hidden_2])),
“出”:tf.Variable (tf.random_normal ([n_classes]))
}
#初始化
预测=multilayer_perceptron (input_tensor、重量偏差)
#定义损失和优化器采用softmax函数
# reduce_mean计算平均误差=tf.reduce_mean (tf.nn损失。softmax_cross_entropy_with_logits(分对数=预测,标签=output_tensor))
优化器=tf.train.AdamOptimizer (learning_rate=learning_rate) .minimize(损失)
#初始化所有变量
init=tf.global_variables_initializer ()
#部署图
与tf.Session税():
sess.run (init)
training_epochs=100
display_step=5
batch_size=1000
#培训
时代的范围(training_epochs):
avg_cost=0。
total_batch=int (len (newsgroups_train.data)/batch_size)
因为我在范围(total_batch):
batch_x batch_y=get_batch (newsgroups_train,我,batch_size)
c, _=sess.run(损失,优化器,feed_dict={input_tensor: batch_x output_tensor: batch_y})
#计算平均损失
avg_cost +=c/total_batch
#每5次时代展示一次损失
如果时代% display_step==0:
打印(“时代:“,‘% d %(+ 1)时代,“损失=?“{:.6f}”.format (avg_cost))
打印(“结束了!”)
#测试模型
correct_prediction=tf.equal (tf。argmax(预测,1),特遣部队。argmax (output_tensor 1))
#计算准确率
精度=tf.reduce_mean (tf。铸造(correct_prediction“浮动”))
total_test_data=https://www.yisu.com/zixun/len (newsgroups_test.target)
batch_x_test batch_y_test=get_batch (newsgroups_test 0 total_test_data)
打印(“精度:精度。eval ({input_tensor: batch_x_test output_tensor: batch_y_test}))




