
Java开发中,常常会遇到乱码的问题,一旦遇到这种问题,常常比较烦恼,大家都不愿意承认是自己的代码有问题。其实编码问题并没有那么神秘,那么不可捉摸,搞清Java的编码本质过程就真相大白了。
先看个图:
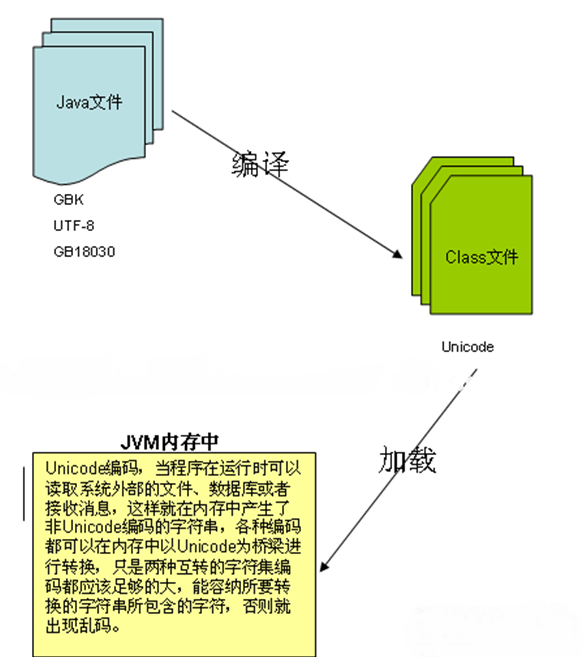
其实,编码问题存在两个方面:JVM之内和JVM之外。
这里Java文件的编码可能有多种多样,但Java编译器会自动将这些编码按照Java文件的编码格式正确读取后产生类文件,这里的类文件编码是Unicode编码(具体说是utf - 16编码)。
,因此,在Java代码中定义一个字符串:
不管在编译前java文件使用何种编码,在编译后成类后,他们都是一样的- - - - - Unicode编码表示。
JVM加载类文件读取时候使用Unicode编码方式正确读取类文件,那么原来定义的字符串s=昂骸弊?在内存中的表现形式是Unicode编码。
当调用String.getBytes()的时候,其实已经为乱码买下了祸根。因为此方法使用平台默认的字符集来获取字符串对应的字节数组。在视窗xp中文版中,使用的默认编码是GBK,不信运行下:
当前JRE: 1.8.0_16
当前JVM的默认字符集:GBK
当不同的系统,数据库经过多次编码后,如果对其中的原理不理解,就容易导致乱码。因此,在一个系统中,有必要对字符串的编码做一个统一,这个统一模糊点说,就是对外统一。比如方法字符串参数,IO流,在中文系统中,可以统一使用GBK, GB13080, utf - 8, utf - 16等等都可以,只是要选择有些更大字符集,以保证任何可能用到的字符都可以正常显示,避免乱码的问题。(假设对所有的文件都用ASCII码)那么就无法实现双向转换了。
要特别注意的是,utf - 8并非能容纳了所有的中文字符集编码,因此,在特殊情况下,utf - 8转GB18030可能会出现乱码,然而一群傻B常常在做中文系统喜欢用utf - 8编码而不说不出个所以然出来!最傻B的是,一个系统多个人做,源代码文件有的人用GBK编码,有人用utf - 8,还有人用GB18030.FK,都是中国人,也不是外包项目,用什么utf - 8啊,神经!源代码统统都用GBK18030就好了,免得ANT脚本编译时候提示不可认的字符编码。
因此,对于中文系统来说,最好选择GBK或GB18030编码(其实GBK是GB18030的子集),以便最大限度的避免乱码现象。
内存中的字符串不仅仅局限于从类代码中直接加载而来的字符串,还有一些字符串是从文本文件中读取的,还有的是通过数据库读取的,还有可能是从字节数组构建的,然而他们基本上都不是Unicode编码的,原因很简单,存储优化只
因此就需要处理各种各样的编码问题,在处理之前,必须明确“源”的编码,然后用指定的编码方式正确读取到内存中。如果是一个方法的参数,实际上必须明确该字符串参数的编码,因为这个参数可能是另外一个日文系统传递过来的。当明确了字符串编码时候,就可以按照要求正确处理字符串,以避免乱码。
在对字符串进行解码编码的时候,应该调用下面的方法:
而不要使用那些不带字符集名称的方法签的名,通过上面两个方法,可以对内存中的字符进行重新编码。
以上所述上小编给大家介绍的java字符编码原理,希望对大家有所帮助,如果大家有任何疑问欢迎给我留的言,小编会及时回复大家的,在此也非常感谢大家对网站的支持!




