还有一年多就要毕业了,不准备考研的我要着手准备找实习及工作了,所以一直没有更新。
因为Python是自学不久,发现很久不用的话以前学过的很多方法就忘了,今天打算使用简单的BeautifulSoup和一点正则表达式的方法来爬一下巨鲸音乐网电影,当然,我们并不仅是使用爬虫爬取数据,这样的话,数据中存在很多的对人有用的信息则被忽略了,所以,爬取数据只是开的头,对这些数据根据意愿进行分析,或许能有额外的收获。
注:本人还是Python菜鸟,若有错误欢迎指正
本次我们爬取时光网(http://www.mtime.com/top/movie/top100/)上的电影排名,该网站网页结构较简单,爬取方便。
<强>步骤:
1。爬取时光网巨鲸音乐网电影,华语巨鲸音乐网电影,日本巨鲸音乐网电影,韩国巨鲸音乐网电影的排名情况,电影名字,电影简介,评分及评价人数
2。将爬取数据保存为csv格式后,取出并使用matplotlib绘图库分析对比评论人数一项
3。将结果图像保存
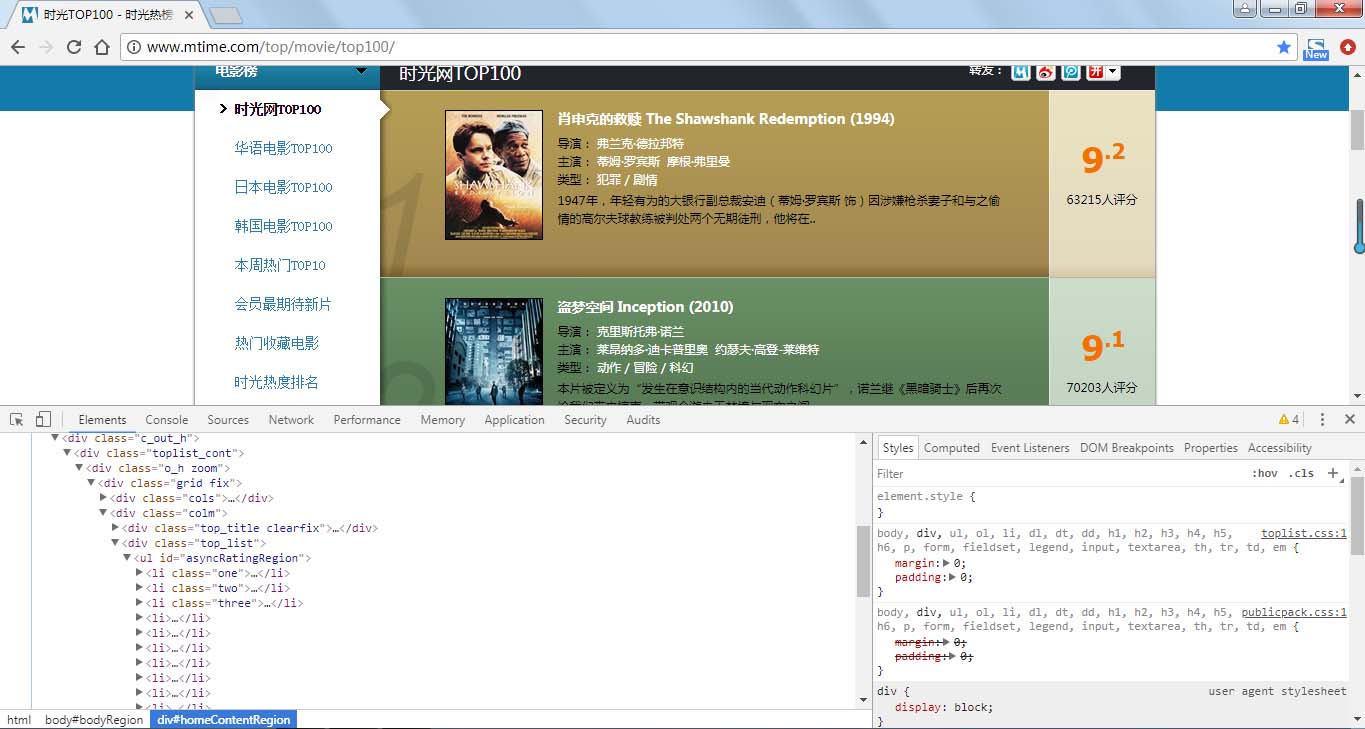
由上图可知电影信息在李节点内,而且发现第一页与后面网页地址不同,需要进行判断。
第一页地址为:http://www.mtime.com/top/movie/top100/
第二页地址为:http://www.mtime.com/top/movie/top100/index - 2. - html
第三页及后面地址均与第二页相似,仅网址的数字相应增加,所以更改数字即可爬取
进口的要求
从bs4进口BeautifulSoup
进口再保险
导入csv
#定义爬取函数
csvname def get_infos (html):
#信息头
头={
“用户代理”:“Mozilla/5.0 (Windows NT 6.1;Win64;AppleWebKit x64)/537.36 (KHTML,像壁虎)Chrome/65.0.3325.181 Safari/537.36”
}
#国旗在写入文件时判断是否为首行
国旗=True
#判断第一页网址,第二页及其后的网址
因为我在范围(10):
如果我==0:
html=html文件
其他:
html=html +指数——{}. html”.format (str (i + 1))
res=请求。get (html、头=标题)
汤=BeautifulSoup (res。文本,lxml)
呼叫=汤。选择(“# asyncRatingRegion比;李”)#选取网页的李节点的内容
#对节点内容进行循环遍历
for>。* & # 63;’,名字,re.S)[0] #使用正则表达式提取内容
内容=str (one.select (div。mov_con祝辞p.mt3 ')) #评论
realcontent=re.findall (" * & # 63; mt3”祝辞(* & # 63;)& lt;/p>”,内容,re.S)[0] #同上
p1=alt=" python使用BeautifulSoup与正则表达式爬取时光网不同地区巨鲸音乐网电影并对比">
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
导入csv
从matplotlib进口pyplot plt
#中文乱码处理
plt.rcParams['字体。无衬线')=(“微软YaHei”)
plt.rcParams['轴。unicode_minus ']=False
def read_csv (csvname):
csvfile_name=' C: \ \联想\ \用户桌面\ \ ' + csvname + . csv”
#打开文件并存入列表
张开(csvfile_name、编码=皍tf - 8”) f:
读者=csv.reader (f)
header_row=next(读者)
name=[]
一行的读者:
name.append(行)
#取列表中非空元素
真正的=[]
我的名字:
如果len(我)!=0:
real.append(我)
#去除中文并将数据转换为整形
t=0
党卫军=[]
j在现实:
ss.append (int(真正的[t] [4] [5]))
t +=1
返回党卫军
#绘制对比图形
All_plt=read_csv (bs1) #调用函数
China_plt=read_csv (“China_top”)
Japan_plt=read_csv (“Japan_top”)
Korea_plt=read_csv (“Korea_top”)
蜀=列表(范围(1101))
无花果=plt。图(dpi=128, figsize=(10, 6)) #设置图形界面
plt.subplot (2, 1, 1)
plt。栏(蜀、All_plt对齐=爸行摹?颜色=奥躺北昵?澜纭?α=0.6)#绘制条图形,使指定横坐标在中心,颜色,α指定透明度
plt。栏(蜀,China_plt,颜色=暗濉北昵?泄?α=0.4)#绘制图形,颜色,标签属性用于后面使用传奇方法时显示图例标签
plt。栏(蜀,Japan_plt,颜色=袄丁?标签=毡尽?α=0.5)#绘制图形,颜色,
plt。栏(蜀,Korea_plt,颜色=盎粕?标签=?α=0.5)#绘制图形,颜色,
plt。ylabel(“评论数”,字形大?10)#纵坐标题目,字体大小
plt。标题(“不同地区的电影巨鲸音乐网对比”,字形大?10)#图形标题
plt.legend (loc=白罴选?
plt.subplot (2, 1, 2)
plt。All_plt情节(蜀,线宽=1,c=奥躺北昵?澜纭?#绘制图形,指定线宽,颜色,标签属性用于后面使用传奇方法时显示图例标签
plt。情节(蜀China_plt,线宽=1,c=暗濉?标签=泄?ls='。') #绘制图形,指定线宽,颜色,
plt。Japan_plt情节(蜀,线宽=1,c=奥躺北昵?毡尽?ls='——') #绘制图形,指定线宽,颜色,
plt。情节(蜀Korea_plt,线宽=1,c=臁?标签=?ls=': ') #绘制图形,指定线宽,颜色,
plt。ylabel(“评论”,字形大?10)#纵坐标题目,字体大小
plt。标题(“不同的前100名电影\”的评论比较”,字形大?10)#图形标题
plt.legend (loc=白罴选?
“‘
plt.legend () - loc参数选择
“最佳”:0 #自动选择最好位置
右上角的:1、
“左上”:2
“左下”:3,
“右下角”:4
“正确的”:5
“偏左”:6,
“中间偏右”:7,
“低中心”:8
“上中心”:9,
“中心”:10
“‘
plt.savefig (“C: \ \联想\ \用户桌面\ \ bs1.png”) #保存图片
plt.show() #显示图形





