
在整理文件时,将多个同类型文档合并是实现文档归类的有效方法,也便于文档管理或者文档传输。当然,也可以对一些比较大的文件进行拆分来获取自己想要的部分文档。可以任意地对文档进行合,并拆分无疑为我们了提供极大的便利。那么在c#语言环境中怎么来实现PDF文档的和被拆分呢?下面将介绍具体的代码操作方法。
<强>所需工具:免费的尖顶。PDF为。net, Visual Studio 2013
一、合并多个PDF文档
<代码>使用系统;
使用Spire.Pdf;
名称空间MergePDF
{
类项目
{
静态void Main (string [] args)
{//创建一组数组实例,数组元素为需要合并的多个PDF文档的路径
String[]=新String [] {" test1的文件。pdf”、“test2。pdf”、“test3。pdf "};//调用方法MergeFiles()合并文档
PdfDocumentBase doc=PdfDocument.MergeFiles(文件);//保存文档
doc.Save(“合并。pdf”, FileFormat.PDF);
}
}
}
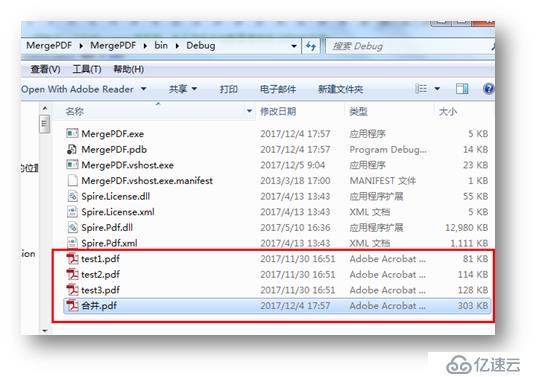
<强>注意:这里合并的PDF文档是以新的一页来合并的文档,目的不是将多个文档合并为具有一定逻辑的文档,而是出于方便文档管理以及其他操作的目的来合并。
二、拆分PDF文档
<强>(一)按每页来拆分
<代码>使用系统;
使用Spire.Pdf;
名称空间SplitPDF1
{
类项目
{
静态void Main (string [] args)
{//初始化一个PdfDocument类实例,并从文件中加载需要被拆分的PDF文档
PdfDocument doc=new PdfDocument (@ " C: \ \用户管理员桌面\ \ test.pdf ");//调用方法分离()方法将PDF文档按页拆分保存
字符串模式="拆分{0}. pdf”;
doc.Split(模式);
}
}
}
拆分结果:
![c#合,并拆分PDF文档”> <br/>拆分的文档个数与原文档页数相同。</p>
<h2>(二)按指定页数拆分</h2>
使用Spire.Pdf <pre> <代码>;
使用Spire.Pdf.Graphics;
使用System.Drawing;
名称空间SplitPDF2
{
类项目
{
静态void Main (string [] args)
{//创建一个PdfDocument类对象,并加载一个现有文的PDF档
PdfDocument pdf=new PdfDocument ();
pdf.LoadFromFile (@“C: \ \管理员桌面\ \用户测试. pdf”);//新建1个PDF文档
PdfDocument pdf1=new PdfDocument ();
PdfPageBase页面;//将现有文的PDF档的第1 - 5页拆分为一个文档
for (int i=0;我& lt;4;我+ +)
{//向新建文档添加与现有文档页面大小一致的页面
页面=pdf1.Pages.Add (pdf.Pages[我]。大小、新PdfMargins (0));//为现有文档的页面创建模板并将模板画到新建文档的页面上
pdf.Pages[我].CreateTemplate ()。画(页面,新PointF (0, 0));
}//保存文档
pdf1.SaveToFile (“1 - 5. - pdf”);//新建第2个PDF文档
PdfDocument pdf2=new PdfDocument ();//将现文有PDF档的第5 - 10页拆分为另一个文档
for (int i=4;我& lt;9;我+ +)
{//向新建文档添加与现有文档页面大小一致的页面
页面=pdf2.Pages.Add (pdf.Pages[我]。大小、新PdfMargins (0));//为现有文档的页面创建模板并将模板画到新建文档的页面上
pdf.Pages[我].CreateTemplate ()。画(页面,新PointF (0, 0));
}//保存文档
pdf2.SaveToFile (“6 - 10. - pdf”);//新建第3个PDF文档
PdfDocument pdf3=new PdfDocument ();//将现文有PDF档的第10 - 15页拆分为另一个文档
for (int i=9;我& lt;14;我+ +)
{//向新建文档添加与现有文档页面大小一致的页面
页面=pdf3.Pages.Add (pdf.Pages[我]。大小、新PdfMargins (0));//为现有文档的页面创建模板并将模板画到新建文档的页面上
pdf.Pages[我].CreateTemplate ()。画(页面,新PointF (0, 0));
}//保存文档
pdf2.SaveToFile (11 - 15. - pdf);
}
}
}
</代码> </pre>
<p> <img src=](/zixun/d/file/jishu/2021-08-18/e71c66b22020c08a9753780b3d1ce115.jpg )
以上内容为本篇文章关于合,并拆分PDF文档的方法讲述。如果喜欢,欢迎转载(转载请注明出处)
感谢浏览。




