
一、需求分析
线上的MySQL服务器,最近有很多慢查询。需要统计出行数大于100年万的表,进行统一优化。
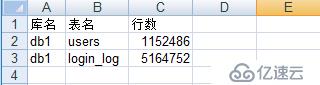
需要筛选出符合条件的表,统计到excel中,格式如下:
库名 表名 行数 db1 用户 1234567二、统计表的行数
统计表的行数,有2中方法:
<编辑> 1。通过查询mysql的information_schema数据库中INFODB_SYS_TABLESTATS表,它记录了innodb类型每个表大致的数据行数 <编辑> 2。从库选择计数(1)名,表名下面来分析一下这2种方案。
第一种方案,不是精确记录的。虽然效率快,但是表会有遗漏!
第二钟方案,才是准确的。虽然慢,但是表不会遗漏。
<编辑>备注:计数(1)其实这1个,并不是表示第一个字段,而是表示一个固定值。
计数(1),其实就是计算一共有多少符合条件的行。
1并不是表示第一个字段,而是表示一个固定值。
其实就可以想成表中有这么一个字段,这个字段就是固定值1,计数(1),就是计算一共有多少个1 .
写入json文件
下面这段代码,是参考我之前写的一篇文章:
<编辑>在此基础上,做了部分修改,完整代码如下:
<代码> # !/usr/bin/env python3
utf - 8编码:
进口pymysql
进口json
康涅狄格州=pymysql.connect (
主机=" 192.168.91.128 " # mysql ip地址
用户="根",
passwd="根",
端口=3306,# mysql端口号,注意:必须是int类型
connect_timeout=3 #超时时间
)
坏蛋=conn.cursor() #创建游标
#获取mysql中所有数据库
cur.execute(显示数据库)
data_all=cur.fetchall() #获取执行的返回结果
#打印(data_all)
dic={} #大字典,第一层
因为我在data_all:
如果我在dic[0]不是:#判断库名不在dic中时
#排序列表,排除mysql自带的数据库
exclude_list=[“sys”、“information_schema”、“mysql”、“performance_schema”)
如果我[0]不是exclude_list: #判断不在列表中时
#写入第二层数据
dic[我[0]]={“名称”:我[0],“table_list”: []}
conn.select_db(我[0])#切换到指定的库中
cur.execute(“显示表”)#查看库中所有的表
ret=cur.fetchall() #获取执行结果
j的ret:
#查询表的行数
cur.execute (' select count(1)从“% s”;“% j [0])
ret=cur.fetchall ()
#打印(ret)
ret k:
打印({tname: j[0],“行”:k [0]})
dic[我[0]][' table_list ']。追加({tname: j[0],“行”:k [0]})
张开(‘tj.json’,‘w’,编码=皍tf - 8”) f:
f.write (json.dumps (dic)
三,写入excel中
<编辑>直接读取tj.json文件,进行写入,完整代码如下:<代码> # !/usr/bin/env python3 utf - 8编码: 进口xlwt 进口json 从进口OrderedDict集合 f=xlwt.Workbook () sheet1=f。add_sheet(“统计”,cell_overwrite_ok=True) row0=["库名”、“表名”,“行数”) #写第一行 因为我在范围(0,len (row0)): sheet1。写(0,我,row0[我]) #加载json文件 张开(“tj。load_f json”、“r”): load_dict=json.load (load_f) #反序列化文件 order_dic=OrderedDict() #有序字典 关键的排序(load_dict): #先对普通字典关键做排序 order_dic[主要]=load_dict(例子)#再写入关键 num=0 #计数器 因为我在order_dic: #遍历所有表 在order_dic j[我](“table_list”): #判断行数大于100年万时 如果j(“行”)的在1000000: #写入库名 sheet1。写(num + 1, 0,我) #写入表名 sheet1。写(num + 1, 1, j [' tname ']) #写入行数 sheet1。写(num + 1 2 j['行']) num +=1 #自增1 f.save (test1.xls)
执行程序,打开excel文件,效果如下:
欢迎大家一起来玩好PY,一起交流.QQ群:198447500




