
这篇文章将为大家详细讲解有关再如何使用,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
现在开发一般都是团队开发,这样就会出现项目同步的问题,代码同步可以通过SVN工具管理起来,那数据库同步怎么办呢?理想的情况下,在开发新项目的时候会首先把业务理清楚,把数据库表设计好,然后将数据库交给专门的人员维护,也就不存在数据库同步的问题了。但实际情况呢?需求从项目开始到项目结束一直在变,很多公司就没有专门的数据库维护人员,数据库大家都在操作,都在修改,如果团队之间沟通及时还好,大家每次更新代码后顺便也更新一下数据库,如果沟通不及时,呵呵(大家自行脑补)…这样数据库不同步的问题就凸显出来了。
<强> 1,概念:
迁徙路线是独立于数据库的应用,管理并跟踪数据库变更的数据库版本管理工具。用通俗的话讲,再经可以像SVN管理不同人的代码那样,管理不同人的sql脚本,从而做到数据库同步。
2支持的数据库类型:
Oracle sql Server, sql Azure, DB2中,DB2 z/OS中,MySQL(包括Amazon RDS), MariaDB,谷歌云sql, PostgreSQL(包括Amazon RDS和Heroku)、红移,Vertica, H2, Hsql,德比,SQLite, SAP HANA, solidDB, Sybase ASE和菲尼克斯。
3, sql脚本的命名规范:
V +版本号(版本号的数字间以“!”或“_"分隔开)+双下划线(用来分隔版本号和描述)+文件描述+后缀名,例如:V2017.9.30__Update。sql .
注:版本号不能相同。
4,再读取sql脚本的默认位置:
项目的源文件夹下的db/迁移目录。
5,指令:
一共就6个基本指令:迁移,干净,信息,验证、基线,修复。
1,不仅支持sql脚本,还支持Java代码直接操作数据库(flyway-core-x.x.x。jar);
2,有Maven插件;
3支持命令行;
4,与春天框结合,很方便地实现应用启动时自动检查并升级数据库的功能。
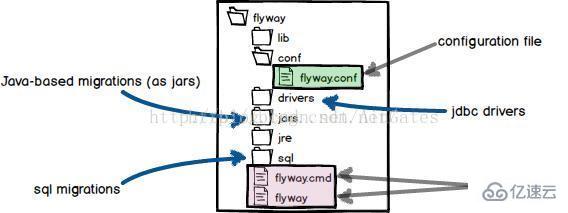
1,解压下载flyway-commandlin版本并解压到本地,结构图如下:
 & lt; !——再——比;
& lt; dependency>
& lt; groupId> org.flywaydb
& lt; artifactId> flyway-core
& lt; version> 4.2.0
& lt; dependency>
& lt; !——再——比;
& lt; dependency>
& lt; groupId> org.flywaydb
& lt; artifactId> flyway-core
& lt; version> 4.2.0
& lt; dependency>
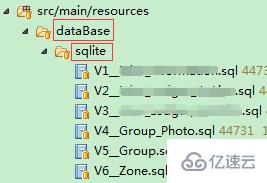
2,在src/main/资源目录下建立存放sql版本文件的路径/sqlite数据库(也可以写默认路径db/迁移),并将sql文件放在下面。
 包com.xxxxxx.flyway;
进口javax.sql.DataSource;
进口org.flywaydb.core.Flyway;
公开课MigrationSqlite {
私人数据源的数据源;
公共空setDataSource(数据源的数据源){
这一点。数据源=数据源;
}
公共空间迁移(){//初始化再经类
再经迁徙路线=new迁徙路线();//设置加载数据库的相关配置信息
flyway.setDataSource(数据源);//设置存放再经元数据数据的表名,默认“schema_version"可,不写
flyway.setTable (“SCHMA_VERSION");//设置再扫描sql升级脚本,java升级脚本的目录路径或包路径,默认“db/migration",可不写
flyway.setLocations(“数据库/sqlite");//设置sql脚本文件的编码,默认“UTF-8"可,不写
flyway.setEncoding (“UTF-8");
flyway.migrate ();
}
}
包com.xxxxxx.flyway;
进口javax.sql.DataSource;
进口org.flywaydb.core.Flyway;
公开课MigrationSqlite {
私人数据源的数据源;
公共空setDataSource(数据源的数据源){
这一点。数据源=数据源;
}
公共空间迁移(){//初始化再经类
再经迁徙路线=new迁徙路线();//设置加载数据库的相关配置信息
flyway.setDataSource(数据源);//设置存放再经元数据数据的表名,默认“schema_version"可,不写
flyway.setTable (“SCHMA_VERSION");//设置再扫描sql升级脚本,java升级脚本的目录路径或包路径,默认“db/migration",可不写
flyway.setLocations(“数据库/sqlite");//设置sql脚本文件的编码,默认“UTF-8"可,不写
flyway.setEncoding (“UTF-8");
flyway.migrate ();
}
}
4,在春天中实例化第3步的java类:
从上面的bean定义中我们可以看的到,我们为flywayMigration这个豆实例注入了一个数据源,再经的所有操作将针对这个数据源进行;同时我们通过init方法属性指定了春天在实例化该bean以后,主动执行该bean的迁移方法,而该方法内会执行再更新数据库的操作。至此,我们达到了在应用启动时,弹簧实例化上下文的时候,在春天实例化flywayMigration这个bean的时候,自动执行再更新数据库的操作。




