
本篇内容介绍了“MySQL中的count(),联盟()和group by语句的用法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
<强>一、MySQL中数()的不同用法
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果数函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。【相关推荐:MySQL视频教程】
1。对于计数(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给服务器层.server层拿到身份证后,判断是不可能为空的,就按行累加
2。对于计数(1)来说,InnoDB引擎遍历整张表,但不取值.server层对于返回的每一行,放一个数字1进入,判断是不可能为空的,按行累加
3。对于数(字段)来说,如果这个字段是定义为not NULL的话,一行行地从记录里面读出这个字段,判断不能为NULL,按行累加,如果这个字段定义允许为零的话,那么执行的时候,判断到有可能是NULL,还要把值取出来在判断一下,不是零才累加
4。对于<代码> count(*) 来说,并不会把全部字段取出来,而是专门做了优化。不取值,<代码> count(*) 肯定不是NULL,按行累加
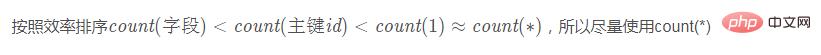
<强>二,联盟执行流程
为了便于量化分析,以下面表t1来举例
分析下面这条SQL语句:
联盟的语义是取这两个子查询结果的并集,并集的意思是这两个集合加起来,重复的行只保留一行

第二行的键=主,说明第二个子句用到了索引id
<李>第三行额外的字段,表示在对子查询的结果集做联盟的时候,使用了临时表
这个语句的执行流程如下:
1。创建一个内存临时表,这个临时表只有一个整型字段f,并且f是主键字段
2。执行第一个子查询,得到这1000个值
3。执行第二个子查询:
拿到第一行id=1000,试图插入临时表中。但由于这1000个值已经存在于临时表了,违反了唯一性约束,所以插入失败,然后继续执行
<李>取到第二行id=999,插入临时表成功
4。从临时表中按行取出数据,返回结果,并删除临时表,结果中包含两行数据分别是1000年和999年
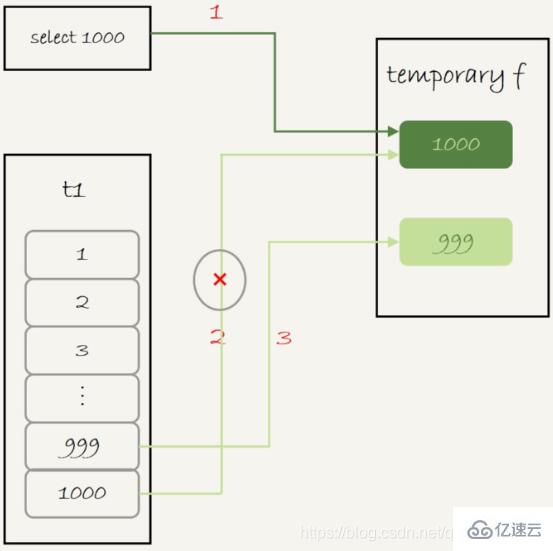
这里的内存临时表起到了暂存数据的作用,而且计算过程还用上了临时表主键id的唯一性约束,实现了联盟的语义
如果把上面的语句中联盟改成联盟所有的话,就没有了去重的语义。这样执行的时候,就依次执行子查询,得到的结果直接作为结果集的一部分,发给客户端,因此也就不需要临时表了

第二行额外的字段显示的是使用索引、表示只使用了覆盖索引,没有用临时表
<强>三、group by语句详解
<强> 1、group by执行流程
还是使用上面的表t1,分析下面这条SQL语句:
这个语句的逻辑是把表t1里的数据,按照id % 10进行分组统计,并按照m的结果排序后输出.explain结果如下:





