
这篇文章主要介绍了复述,如何扩容,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
<强>方案一:
首先想到的是,增加复述,服务器的数量,在客户端对存储的关键进行散列运算,存入不同的复述,服务器中,读取时,也进行相同的哈希运算,找到对应的复述,服务器,可以解决问题,但是不好的地方:
第一,客户端要改动代码;
第二,需要客户端记住所有的复述,服务器的地址;
这个方案可以使用,但能不能不用改动代码就能实现扩容呢?
<强>方案二:
搭建一个集群,由于复述,服务器使用的版本低于3.0,不支持集群,只能通过使用代理,就想到了有名的复述,代理twemproxy。
twemproxy的性能也是杠杠滴,虽然是代理,但它对访问性能的影响非常小,连复述,作者都推荐它。
twemproxy使用方便,对于一个新手来说,不到一个小时就能学会使用,而且关键是不用改动客户端代码,几乎支持所有的复述,命令和管道操作,只需要改下客户端的配置文件中配置的复述的IP和端口,由原来的复述的IP和端口改成twemproxy服务的IP和端口。
客户端不需要考虑散列的问题,这些twemproxy会做,客户端就像操作一台复述一样。
上面用了“几乎”这个词,因为有些命令,比如“*“钥匙就不支持
很快部署了好了twemproxy和后面跟着的四个复述,机器,压测发现,后面的四台复述的CPU使用率降下来了,但新问题来了,twemproxy也是单进程的!性能瓶颈又跑到twemproxy上来了!
<强>方案三:
对复述的访问分为写和读,类似生产者和消费者,再仔细分析,发现写的少,读的相对多些,这就可以将读写分离,写的往主的写,读的从备的读,遇到的情况恰好是读和写是两个服务,做到读写分离通过改下配置信息就可以很简单的做的到,,这样分散了主复述的压力。
这里对复述的访问压力有好转,但不是长久之计,比如遇到举办活动,数据量增大时,还是会有性能的风险。
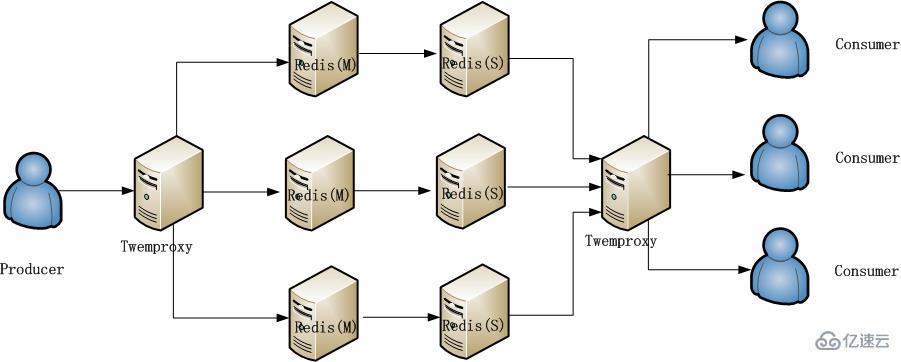
最终采用的方法是综合方案二和三,如下图所示:
 感谢你能够认真阅读完这篇文章,希望小编分享复述,如何扩容内容对大家有帮助,同时也希望大家多多支持,关注行业资讯频道,遇到问题就找,详细的解决方法等着你来学习!
感谢你能够认真阅读完这篇文章,希望小编分享复述,如何扩容内容对大家有帮助,同时也希望大家多多支持,关注行业资讯频道,遇到问题就找,详细的解决方法等着你来学习!




