
介绍
这篇文章主要讲解了“Python爬虫中的urllib和请求有什么区别”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python爬虫中的urllib和请求有什么区别”吧!
1,获取网页数据
第一步,引入模块。
两者引入的模块是不一样的,这一点显而易见的。

第二步,简单网页发起的请求。
urllib是通过urlopen方法获取数据。
请求需要通过网页的响应类型获取数据。

第三步,数据封装。
对于复杂的数据请求,我们只是简单的通过urlopen方法肯定是不行的。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃的苦,建议你可以联系维:762459510,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
urllib中,我们知道对于有反爬虫机制的网站,我们需要对URL进行封装,以获取到数据。我们可以回顾下前几节课的内容:
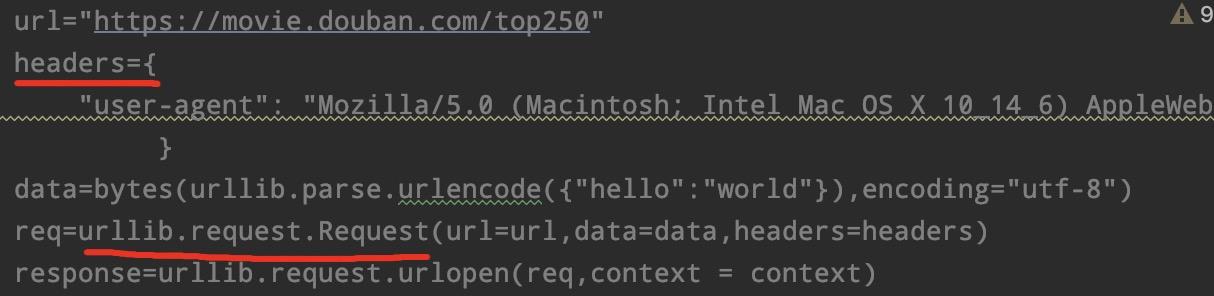
请求模块中,就不需要这么复杂的操作,直接在第二步中,加入参数头即可:

2,解析网页数据
urllib和请求都可以通过bs4和再保险进行数据的解析,请求还可以通过xpath进行解析。具体解析方法之后会详解
3。保存数据
urllib需要引入xlwt模块进行新建表格,表板格写入数据。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃的苦,建议你可以联系维:762459510,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~

请求通过与…直接虚入数据:

感谢各位的阅读,以上就是“Python爬虫中的urllib和请求有什么区别”的内容了,经过本文的学习后,相信大家对Python爬虫中的urllib和请求有什么区别这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是,小编将为大家推送更多相关知识点的文章,欢迎关注!




