
这篇文章主要介绍“网络浏览器的工作原理是什么”,在日常操作中,相信很多人在网页浏览器的工作原理是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答“网络浏览器的工作原理是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
网页浏览器通过向URL发送网络请求来访问web服务器资源,并以交互性的方式展示这些内容。基本操作包括获取,处理,显示和存储。常见的浏览器包括,ie, Firefox,谷歌Chrome, Safari和Opera等。
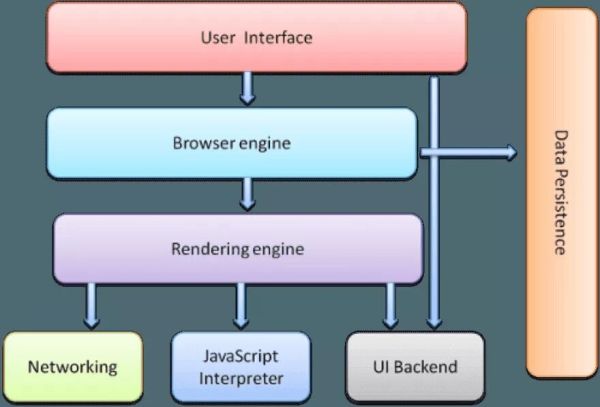
浏览器架构图
浏览器主要由以下几个部分组成:
用户界面
<李>浏览器引擎
<李>渲染引擎
<李>数据存储层
<李>界面端
<李>JavaScript解析器(脚本引擎)
<李>网络层
<强>用户界面
这是用户与浏览器发生交互的区域。浏览器的外观没有特定的标准,HTML5规范没有规定UI,元素该长什么样,但是列了一些常见元素:地址栏,个人信息栏,滚动条,状态栏和工具栏等。
<强>浏览器引擎
它提供了UI与底层渲染引擎之间的接口,根据用户交互进行查询和操控渲染引擎,提供初始化加载,URL的方法,并负责重新加载,返回和前进等操作。
<强>渲染引擎
渲染引擎负责在屏幕上显示网页内容。渲染引擎的主要工作是解析HTML。渲染引擎默认可展示,HTML、XML和图片,还可以通过插件或扩展程序支持其他数据类型。
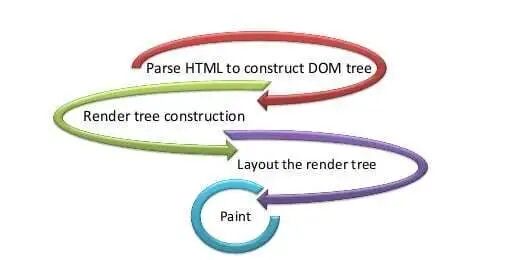
渲染引擎工作过程
现代浏览器使用不同的渲染引擎:
壁虎:Firefox
Webkit: Safari
眨眼:Chrome, Opera(15以版上)。
可以参考这篇:各种浏览器引擎傻傻分不清楚?终于有人说明白了!
web 内容渲染过程大致如下:
HTML 数据转成 DOM
来自网络层的请求内容在渲染引擎中接收(通常是 8 kb 的块),然后将原始字节转换为 HTML 文件中的字符(基于字符编码)。接着词法分析器进行词法分析,将输入分解为各种标记(token)。在标记化过程中,文件中的每个开始和结束标签都被记录下来。它知道如何去掉不相关的字符,比如空格和换行符。
接着,解析器进行语法分析,通过分析文档结构,应用语言语法规则构造解析树。解析过程是迭代进行的。它向词法分析器请求新的 token,如果匹配语法规则,token 就被添加到解析树中。然后再请求另一个 token。如果没有匹配的规则,解析器将在内部存储 token,并不断请求新 token,直到找到匹配所有内部存储 token 的规则。如果没有找到规则,解析器将抛出异常,说明文档无效,包含语法错误。
这些节点在 DOM(文档对象模型)树数据结构中互相链接,建立父子关系、相邻兄弟关系。
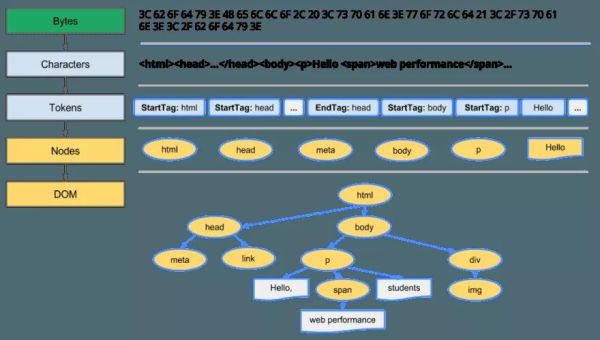
dom-tree
CSS 数据转成 CSSOM
CSS 数据原始字节被转换成字符、token、节点,最终变成 CSSOM(CSS 对象模型)。CSS 的层级特性决定了元素会应用什么样式。元素的样式数据可以来自父元素(通过继承),也可以直接在元素上设置。浏览器需要递归遍历 CSS 树结构来确定特定元素的样式。
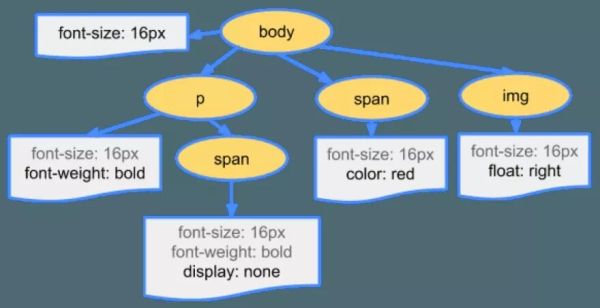
cssom-tree
DOM 与 CSSOM 组成渲染树
DOM 树包含了 HTML 元素之间的关系信息,CSSOM 树则包含了这些元素的样式信息。从根节点开始,浏览器会遍历每一个可见节点。有些节点是隐藏的(通过 CSS 控制),不会出现在渲染结果中。对于每个可见节点,浏览器找到 CSSOM 中定义的相关规则进行匹配,最终这些节点会带着内容和样式出现在渲染树中。
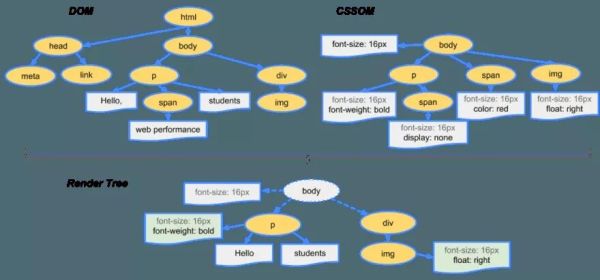
render-tree
布局
接下来进行内容布局。内容的实际尺寸和位置需要经过计算才能渲染到页面上(浏览器视口)。这个过程也叫重排(reflow)。HTML 采用基于流的布局模型,也就是说大部分情况下,几何位置是一次性计算出来的(内容大小或位置发生变化,需要重新计算)。这个过程是从文档根元素开始,递归完成的。




