
本篇内容主要讲解”分库分表与NewSQL怎么选择”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习”分库分表与NewSQL怎么选择”吧!
<>强NewSQL数据库先进在哪儿吗?
首先关于“中间件+关系数据库分库分表”算不算NewSQL分布式数据库问题,国外有篇论文pavlo-newsql-sigmodrec: https://db.cs.cmu.edu/papers/2016/pavlo-newsql-sigmodrec2016.pdf
如果根据该文中的分类,扳手,TiDB, OB算是第一种新架构型,Sharding-Sphere,字符集,DRDS,等中间件方案算是第二种(文中还有第三种云数据库,本文暂不详细介绍)。
基于中间件(包括SDK和代理两种形式)+传统关系数据库(分库分表)模式是不是分布式架构?
我觉得是的,因为存储确实也分布式了,也能实现横向扩展。但是不是“伪“分布式数据库?从架构先进性来看,这么说也有一定道理。
“伪“主要体现在中间件层与底层DB重复的SQL解析与执行计划生成,存储引擎基于B +树等,这在分布式数据库架构中实际上冗余低效的。
为了避免引起真伪分布式数据库的口水战,本文中NewSQL数据库特指这种新架构NewSQL数据库。
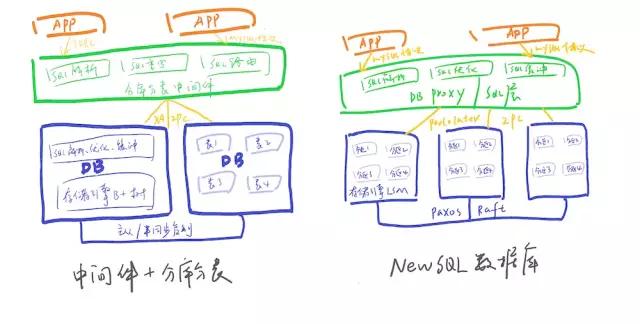
NewSQL数据库相比中间件+分库分表的先进在哪儿吗?画一个简单的架构对比图:
传统数据库面向磁盘设计,基于内存的存储管理及并发控制,不如NewSQL数据库那般高效利用。
<李>中间件模式SQL解析,执行计划优化等在中间件与数据库中重复工作,效率相比较低。
<李>NewSQL数据库的分布式事务相比于XA进行了优化、性能更高。
<李>新架构NewSQL数据库存储设计即为基于Paxos(或,筏)协议的多副本,相比于传统数据库主从模式(半同步转异步后也存在丢数问题),在实现了真正的高可用,高可靠(RTO<30年代,RPO=0)。
<李>NewSQL数据库天生支持数据分片,数据的迁移,扩容都是自动化的,大大减轻了DBA的工作,同时对应用透明,无需在SQL指定分库分表键。
这些大多也是NewSQL数据库产品主要宣传的点,不过这些看起来很美好的功能是否真的如此吗?接下来针对以上几点分别阐述下的我的理解。
<>强分布式事务
首先要说的就是分布式事务:这是一把双刃剑。
<强>帽限制
想想更早些出现的NoSQL数据库为何不支持分布式事务(最新版的MongoDB等也开始支持了),是缺乏理论与实践支撑吗?
并不是,原因是帽定理依然是分布式数据库头上的颈箍咒,在保证强一致的同时必然会牺牲可用性的或分区容忍性p .
为什么大部分NoSQL不提供分布式事务吗?那么NewSQL数据库突破帽定理限制了吗?并没有。
NewSQL数据库的鼻主谷歌扳手(目前绝大部分分布式数据库都是按照扳手架构设计的)提供了一致性和大于5个9,的可用性,宣称是一个“实际上是CA”的。
其真正的含义是系统处于CA,状态的概率高由于网络分区导致的服务停用的概率非常小,究其真正原因是其打造私有全球网保证了不会出现网络中断引发的网络分区。
其中提到:分布式系统中,您可以知道工作在哪里,或者您可以知道工作何时完成,但您无法同时了解两者;两阶段协议本质上是反可用性协议。
<强>完备性
两阶段提交协议是否严格支持酸,各种异常场景是不是都可以覆盖吗?
2 pc在提交阶段发送异常,其实跟最大努力一阶段提交类似也会有部分可见问题,严格讲一段时间内并不能保证了原子性和C一致性(待故障恢复后,复苏机制可以保证最终的A和C)。
完备的分布式事务支持并不是一件简单的事情,需要可以应对网络以及各种硬件包括网卡,磁盘、CPU、内存,电源等各类异常,通过严格的测试。
之前跟某友商交流,他们甚至说目前已知的NewSQL,在分布式事务支持上都是不完整的,他们都有案例跑不过,圈内人士这么笃定,也说明了分布式事务的支持完整程度其实是层次不齐的。
但分布式事务又是这些NewSQL数据库的一个非常重要的底层机制,跨资源的DML、DDL等都依赖其实现,如果这块的性能,完备性打折扣,上层跨分片,SQL执行的正确性会受到很大影响。
<>强性能
传统关系数据库也支持分布式事务XA,但为何很少有高并发场景下用呢?
因为XA的基础两阶段提交协议存在网络开销大,阻塞时间长,死锁等问题,这也导致了其实际上很少大规模用在基于传统关系数据库的OLTP系统中。




