
本文实例讲述了mysql索引覆盖。分享给大家供大家参考,具体如下:
<>强索引覆盖
如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据。这种查询速度非常快,称为“索引覆盖”。
假设有一张t15表,在表中建立了一个联合索引:cp (cat_id、价格)
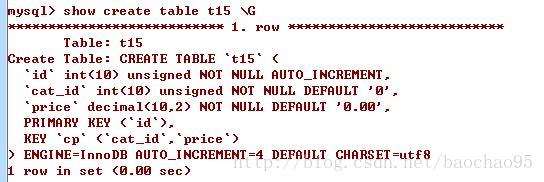
当我们使用下面的sql语句,会出现索引覆盖的情况。不信我们可以来查看一下,这里的额外中显示了使用索引、表示这条sql语句刚好用到了索引覆盖。

在来看一题,创建一张t11表,在邮件中列有一个索引
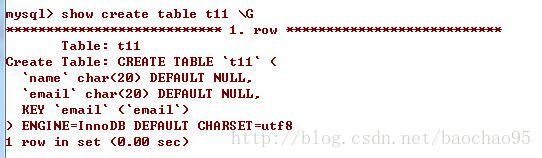
假设我们用这样的查询语句:
查询分析:

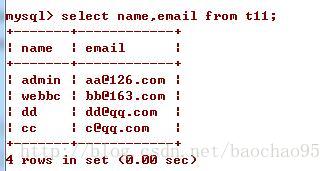
首先看一下,这里有使用索引,说明这里使用到了索引覆盖,而possible_keys为零的原因是因为,使用到了mysql中的函数,所以在查询的时候并没有使用邮件到索引,但关键是却为电子邮件,表示了使用到了索引进行排序,不信我把数据打印看看。

这里的数据是经过排序的。原本的数据是这样的。
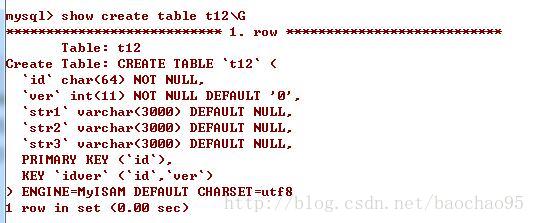
索引覆盖的问题
表中有几个很长的字段varbinary(3000),在id、版本上有联合索引,共10000条数据
为什么<代码>从订单的id选择id> 而<代码>选择id从订单的id、版本非常快
<强>疑问: id (id、版本)都有索引,选择id应该都产生“索引覆盖”的效果,为什么前者慢,而后快?
<>强思路: innodb聚簇与myisam索引的不同,索引覆盖这2个角度来考虑
(1)假设此表使用的是Myisam的索引,那么这两条sql语句都不需要回行查找数据,那么他们的速度应该差不多。
(2)假设此表使用的是InnoDB的索引,那么从订单的id选择id这句sql使用到了主键索引,因为InnoDB的每个主键都挂载这每行的数据,并且本题中还有几个特别大的字段,所以会在查找id的时候需要走的相对慢;而从id的顺序,选择id版本这句sql使用到了id、版本联合索引,在InnoDB存储引擎中,次索引保存的是对主键索引的应用,所以次索引不挂载该行的数据,那么在(id、版本)索引中查找id会快,当找到对应的节点树时,只需要再次查找到主键索引的位置,即可拿到该行的数据,这样比较快。
<>强推断:
(1)表如果是myisam引擎,2个语句,速度不会有明显差异。
(2)innodb表因为聚簇索引,id索引要在磁盘上跨N多块,导致速度慢。
(3)即使innodb引擎,如果没有那几个varbinay长列,2个语句的速度也不会有明显差异。
病人表,存储引擎为MyISAM,有主键索引和(id、版本)符合索引,还有几个大的变长字段,测试推论1
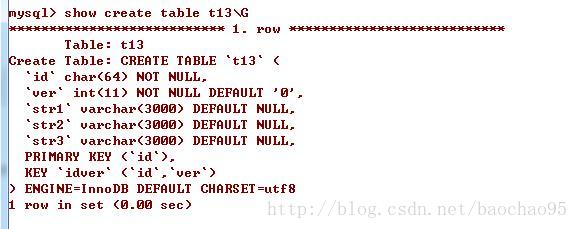
t13表,存储引擎为InnoDB,有主键索引和(id、版本)符合索引,还有几个大的变长字段推论2
t14表,存储引擎为InnoDB,有主键索引和(id、版本)符合索引,没有几个大的变长字段推论3

病人,t13 t14每张表中都有1 w条数据,然后进行测试,测试结果如下,我们的推论是正确的。




