
在此之前,我们先在我们的数据库中插入万10条数据。数据的格式是这样的:
解释方法是用来查看<代码> db.collecion.find() 的一些查询信息的,例如:
解释方法有个可选的参数冗长,是个字符串,他表示的是冗长的模式。一共分3种为模式:
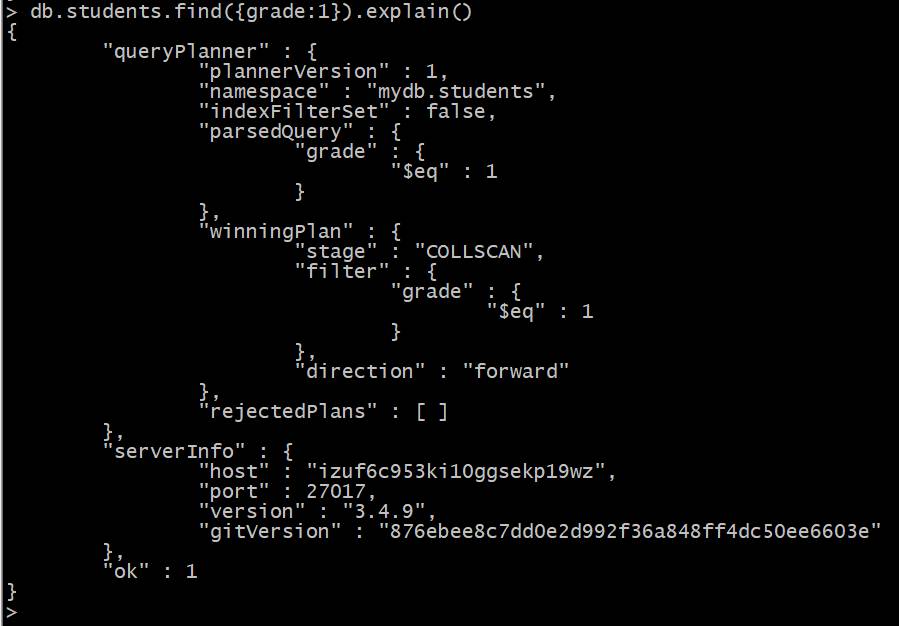
queryPlanner:默认参数,详细说明查询优化器选择的计划并列出被拒绝的计划,例如:
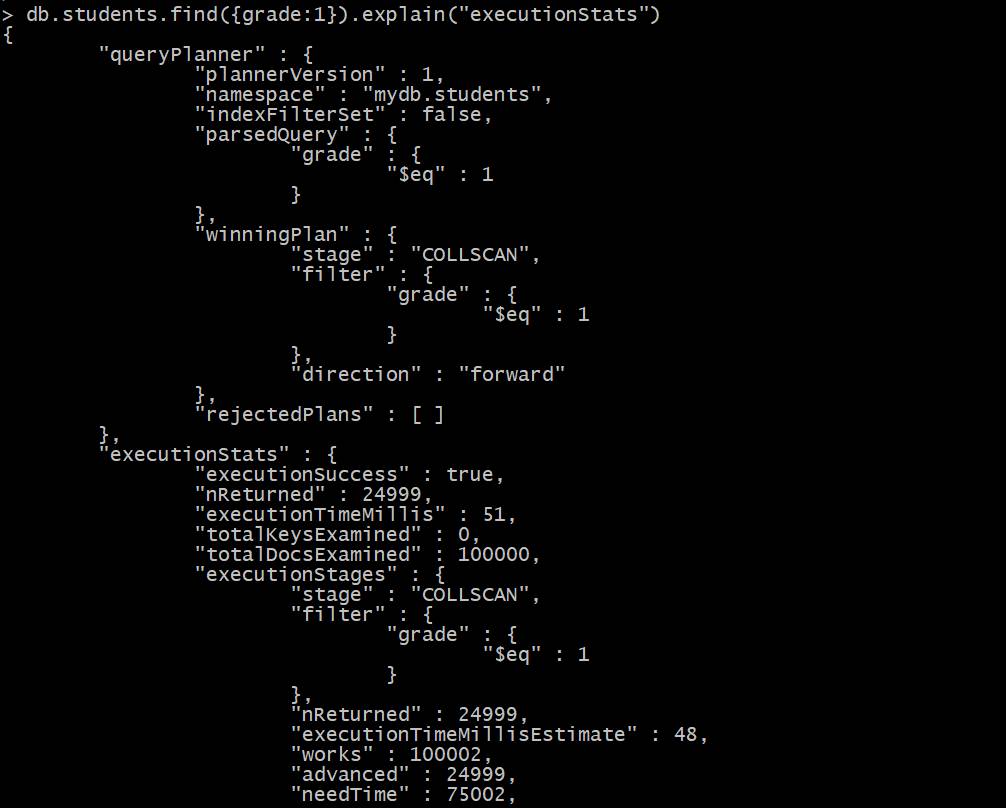
executionStats: MongoDB运行查询优化器选择获胜的计划,执行计划,完成并返回成功,统计描述的胜利计划的执行。例如:
 db.setProfilingLevel (2)
db.getProfilingLevel ()
db.setProfilingLevel (2)
db.getProfilingLevel ()

分析一共分为3个级别:
-
<李> 0 -不开启。
<李> 1 -记录慢命令(默认为在100 ms)
<李> 3 -记录所有命令李
概要记录在级别1时会记录慢命令,那么这个慢的定义是什么& # 63;上面我们说到其默认为100毫秒,当然有默认就有设置,其设置方法和级别一样有两种,一种是通过添加-slowms启动参数配置。第二种是调用<代码> db.setProfilingLevel>
开启剖析功能后,系统会把相关命令详细信息记录到当前数据库的<代码> system.profile>
其中,米尔斯就是命令耗时记录。 由于我们设置的级别是2,所以所有命令都有记录,现在我们把他改为级别1,且只记录耗时20毫秒以上的记录: 然后我们再执行一下聚合查询,查看下耗时时间: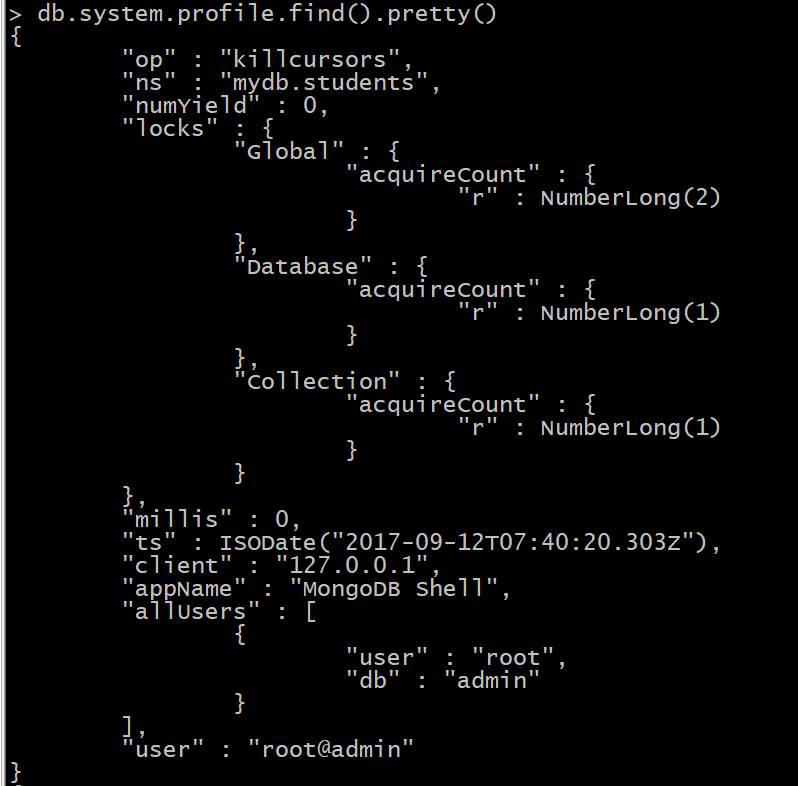

MongoDB如何查询耗时记录的方法详解




