
介绍 #,这里我们使用的是鸢尾花数据集(iris)
数据(iris)
头(iris)
Sepal.LengthSepal.WidthPetal.LengthPetal.WidthSpecies15.13.51.40.2setosa24.93.01.40.2setosa34.73.21.30.2setosa44.63.11.50.2setosa55.03.61.40.2setosa65.43.91.70.4setosa图书馆(dplyr)
库(sqldf)
#,为数据集增加序号列(id)
虹膜id 美元;& lt;作用;c (1: nrow (iris))
#,将鸢尾花数据集中70%的数据划分为训练集
iris_train & lt;作用;sample_frac(虹膜,0.7,replace =,真的)
#,使用sql语句将剩下的30%花费为测试集
iris_test & lt;作用;sqldf (“;
,,,select *
,才能得到虹膜
,,,where id not 拷贝(
,,,select id
,才能得到iris_train
,,,)
,,,,)
#,去除序号列(id)
iris_train & lt;作用;iris_train [6]
iris_test & lt;作用;iris_test [6] #,导入无监督分箱包——infotheo
库(infotheo)
#,分成几个区域
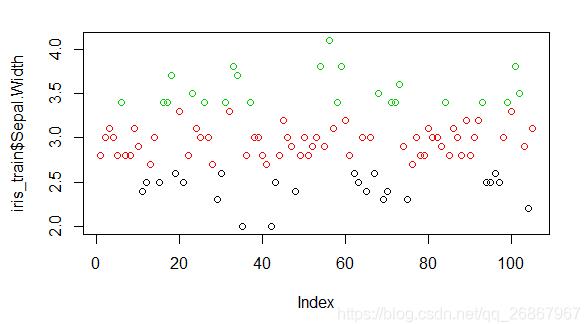
nbins & lt;作用;3 # # #,等宽分箱的原理非常简单,就是按照相同的间距将数据分成相应的等分
#,将连续型数据分成三份,并以1、2、3赋值
equal_width & lt;作用;离散化(iris_train Sepal.Width美元,“equalwidth", nbins)
# # #,查看分箱情况
#,查看各分类数量
表(equal_width)
#,用颜色表明是等宽分箱
情节(iris_train Sepal.Width美元,col =, equal_width X美元)
# # #,保存每个等分切割点的值(阙值)
#,计算各个分类相应的切割点
width & lt;安康;(max (iris_train Sepal.Width美元)分钟(iris_train Sepal.Width美元))/nbins
#,保存阙值
depreciation & lt;安康;width *, c (1: nbins), +, min (iris_train Sepal.Width美元) # # #,等频分箱是将数据均匀的分成相应的等分(数量不一定是完全相同的)
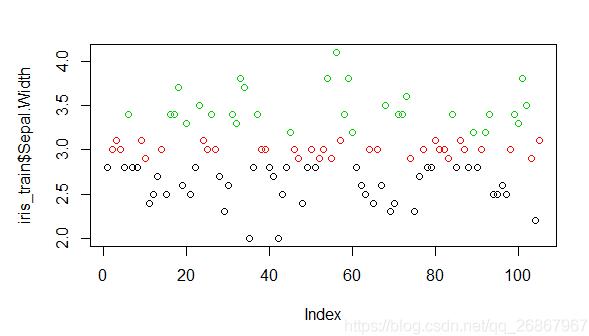
#,将连续型数据分成三份,并以1、2、3赋值
equal_freq & lt;作用;离散化(iris_train Sepal.Width美元,“equalfreq", nbins)
# # #,查看分箱情况
#,查看各分类数量
表(equal_width)
#,用颜色表明是等频分箱
情节(iris_train Sepal.Width美元,col =, equal_freq X美元)
# # #,保存每个等分切割点的值(阙值)
data & lt;作用;iris_train Sepal.Width美元(订单(iris_train Sepal.Width美元))
depreciation & lt;作用;as.data.frame(表(equal_freq)) $频率 #, kmeans分箱法,先给定中心数,将观察点利用欧式距离计算与中心点的距离进行归类,再重新计算中心点,直到中心点#,不再发生变化,以归类的结果做为分箱的结果。
#,将连续型数据分成三份,并以1、2、3赋值
k_means & lt;安康;kmeans (iris_train Sepal.Width美元,nbins)
#,查看各分类数量
表(k_means集群美元)
#,查看实际分箱状况
美元k_means集群
#,保存阙值
#,(),牧师的作用是倒置数据框
#,统一从左往右,从大到小
depreciation & lt;作用;牧师(k_means中心美元)
如何在R语言中实现数据预处理操作?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
一项目环境
开发工具:RStudio
R: 3.5.2
相关包:infotheo,离散化,smbinning, dplyr, sqldf
二、导入数据
Sepal.LengthSepal.WidthPetal.LengthPetal.WidthSpecies15.13.51.40.2setosa24.93.01.40.2setosa34.73.21.30.2setosa44.63.11.50.2setosa55.03.61.40.2setosa65.43.91.70.4setosa
相关数据解释:
Sepal.Length:萼片长度
Sepal.Width:萼片宽度
Petal.Length:花瓣长度
花瓣。宽度:花瓣宽度
物种:鸢尾花品种
三,数据划分
【注】:这里使用到sqldf包的函数sqldf函数来时间在R语言中使用SQL语句
四,无监督分箱
常见的几种无监督分箱方法
等宽分箱法
等频分箱法
kmeans分箱法
1,分箱前准备法
2,等宽分箱法

3,等频分箱

4, kmeans分箱法





