
<>强索引的说明
5,逻辑,或者效率高
6,查看索引在建在那表,列:
,,,从user_indexes select *;
,,,从user_ind_columns select *;
oracle 索引结构:
索引结构
甲骨文索引分为两大类结构:
<强> B树索引结构& lt; balance>
类似于字典查询,最后到叶块,存的是数据rowid和数据项
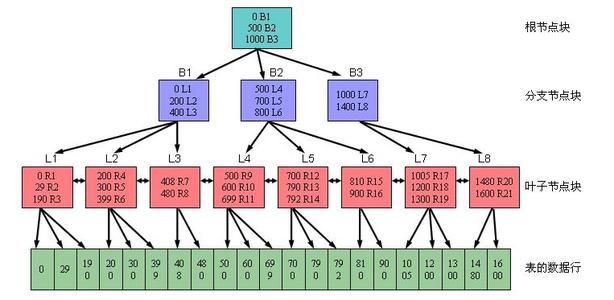
1。叶块之间使用双向链连接,为了可以范围查询。
2。删除表行时,索引叶块也会更新,但只是逻辑更改,并不做物理的删除叶块。
3。索引叶块不保存表行键值null的信息。
位图索引结构& lt; bitmap>
在甲骨文中是根据rowid来定位记录的,因此,我们需要引入开始rowid和结束rowid,通过rowid开始,结束rowid和二进制位的偏移,我们就可以非常快速的计算出二进制位所代表的表记录rowid。位图索引的最终逻辑结构如下图:

我们称每一单元的& lt;关键,startrowid,结束rowid, bitmap>为一个位图片段。当我们修改某一行数据的时候,我们需要锁定该行列值所对应的位图片段,如果我们进行的是更新操作,同时还会锁定更新后新值所在的位图片段,例如我们将列值从01修改为03,就需要同时锁定01和03位图片段,此时如果有其他用户需要修改与01或者03关联的表记录上的索引字段,就会被阻塞,因此位图索引不适合并发环境,在并发环境下可能会造成大量事务的阻塞。
建立索引的方式:
1。唯一索引:键值不重复
创建唯一索引doctor_index t_doctor (empno)
index 下降;doctor_index
2。一般索引:键值可重复
上创建索引doctor_index t_doctor (empno)
index 下降;doctor_index
3。复合索引:绑定了多个列
创建索引doctor_index提醒t_doctor (empno,工作)
index 下降;doctor_index
4。反向索引:为避免平衡树索引热块,如t_doctor表中empno开头都是“7”,这样构建索引树的时候,很可能会把所有数据分配到一个块里,使用反向索引,避免此类问题,使索引树分布均匀
创建索引doctor_index提醒t_doctor (empno)反向
index 下降;doctor_index
5。函数索引:查询时必须用到这个函数,才会使用到
创建索引func_index提醒t_doctor(低(empno))
——select * from t_doctor低(empno)=& # 39;莉娜# 39;
index 下降;func_index
6。压缩索引:不常用
创建索引doctor_index提醒t_doctor (empno)压缩
index 下降;doctor_index
7。升序降序索引:
创建索引doctor_index提醒t_doctor (empno desc,工作asc)
index 下降;doctor_index
索引碎片问题
在甲骨文文档里并没有清晰的给出索引碎片的量化标准,甲骨文建议通过段顾问(段顾问)解决表和索引的碎片问题,如果你想自行解决,可以通过查看index_stats视图,当以下三种情形之一发生时,说明积累的碎片应该整理了(仅供参考)。
,
1。高度祝辞=4,,
2 PCT_USED<50%,,
3 DEL_LF_ROWS/LF_ROWS> 0.2
改变指数ind_1重建[网络][表空间名称];




