并行复制存世已多年,但是在实际应用场景中的使用并不常见。这次很幸运,我们刚好遇到一个客户,主的写入工作量非常大,但是从难以跟上,在这种情况下,我建议它使用并行从属线程。
那么,如何衡量并行复制是否在客户的场景中发挥了作用?对于客户业务能够带来多大的帮助?下面我们就一起来看看吧!
在客户业务场景中,slave_parallel_workers是0,很明显我应该去增大,但增大的幅度是多少呢?1还是10,这个问题我们会在另一篇文章中解释,先说一下本文的场景中,我们将slave_parallel_workers调整到40了。
同时,我们对奴隶还做了以下更改:
<前> 时间=slave_parallel_type LOGICAL_CLOCK; 时间=slave_parallel_workers 40; 时间=slave_preserve_commit_order ; 之前40个线程听起来是很多,但是这是取决于特定的工作负载的,如果事务是独立的,那么它就可能派上用场。
接下来,我们再来看看哪些线程在工作:
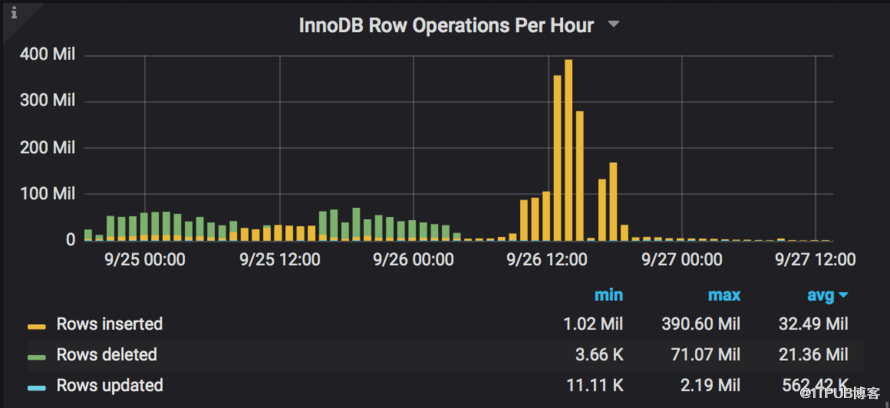
<前> mysql>, SELECT performance_schema.events_transactions_summary_by_thread_by_event_name.THREAD_ID AS THREAD_ID ,performance_schema.events_transactions_summary_by_thread_by_event_name.COUNT_STAR AS COUNT_STAR 得到performance_schema.events_transactions_summary_by_thread_by_event_name WHERE performance_schema.events_transactions_summary_by_thread_by_event_name.THREAD_ID (SELECT performance_schema.replication_applier_status_by_worker.THREAD_ID 得到performance_schema.replication_applier_status_by_worker); + - - - - - - - - - - - - - - - - - - - - - - - - + | |,THREAD_ID COUNT_STAR | + - - - - - - - - - - - - - - - - - - - - - - - - + |,25882,|,442481 | |,25883,|,433200 | |,25884,|,426460 | |,25885,|,419772 | |,25886,|,413751 | |,25887,|,407511 | |,25888,|,401592 | |,25889,|,395169 | |,25890,|,388861 | |,25891,|,380657 | |,25892,|,371923 | |,25893,|,362482 | |,25894,|,351601 | |,25895,|,339282 | |,25896,|,325148 | |,25897,|,310051 | |,25898,|,292187 | |,25899,|,272990 | |,25900,|,252843 | |,25901,|,232424 | + - - - - - - - - - - - - - - - - - - - - - - - - + 之前从上述代码中,我们可以看到哪些线程是在工作,但是这些线程真的加速复制了吗?奴隶能在同一时间内写出更多的东西吗?
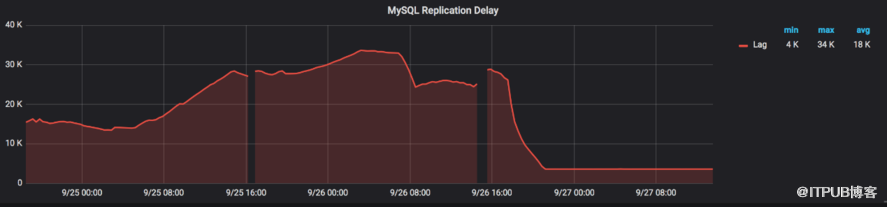
先来看一下复制滞后:
 之前
之前
结果显示: