
小编给大家分享一下python如何使用XPath解析数据爬取起点小说网数据,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获、下面让我们一起去了解一下吧!
python的数据类型:1。数字类型,包括int(整型),长(长整型)和浮子(浮点型)。2。字符串,分别是str类型和unicode类型。3。布尔型,Python布尔类型也是用于逻辑运算,有两个值:True(真)和虚假的(假)。4。列表,列表是Python中使用最频繁的数据类型,集合中可以放任何数据类型。5。元组,元组用“()”标识,内部元素用逗号隔开。6。字,字典典是一种键值对的集合。7。集合,集合是一个无序的,不重复的数据组合。
1。xpath的介绍
xpath是一门在XML文档中查找信息的语言
优点:
可以在XML中找信息
<李>支持HTML的查找
<李>可以通过元素和属性进行导航
但是xpath需要依赖XML的库,所以我们需要去安装lxml的库。
安装lxml库
我们先要安装lxml的库,直接在pycharm里安装即可:
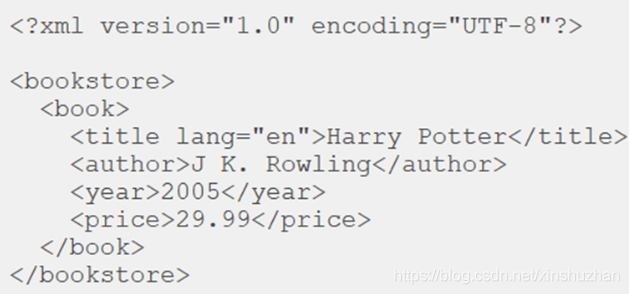
XML的树形结构:
元素——元素,属性——文本
使用xpath选取节点:
节点名:选取此节点的所有节点
<李>/从根节点选择
<李>//从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置
<李>。选择当前节点
<李>. .选择当前节点的父节点(此处是两个点,浏览器默认显示3个. .)
<李>/text()获取当前路径下的文本内容
<李>/@xxx提取当前路径下标签的属性值
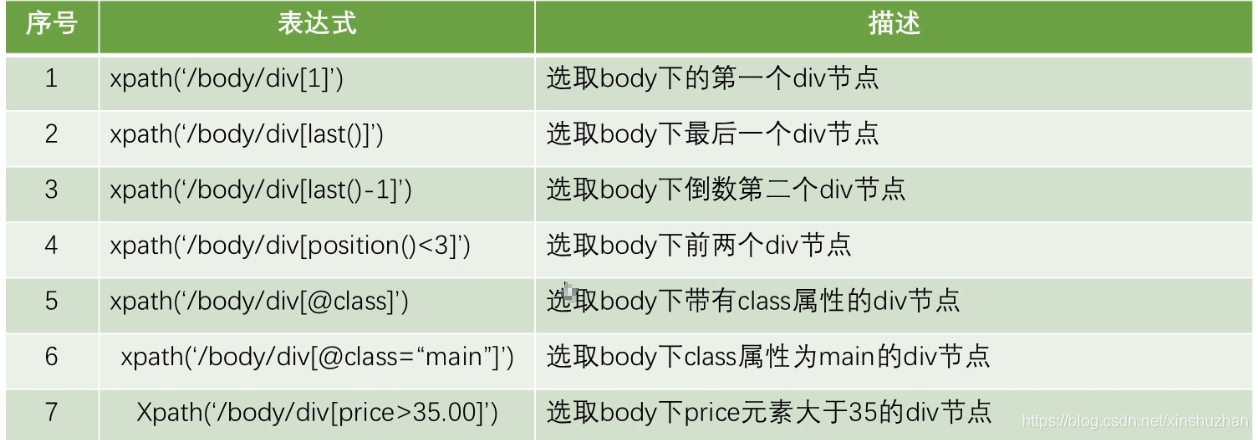
选取节点的表达式举例:
2。爬取起点小说网
在浏览器中获取书名和作者测试
在谷歌里安装一个xpath的插件

在html中查找book-mid-info
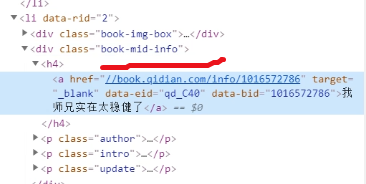
我们要获取小说的名称:也就是//div [@class=& # 39; book-mid-info& # 39;]/h5//txt ()

再加一个获取

使用xpath获取起点小说网的数据
以上是“python如何使用XPath解析数据爬取起点小说网数据”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注行业资讯频道!




