
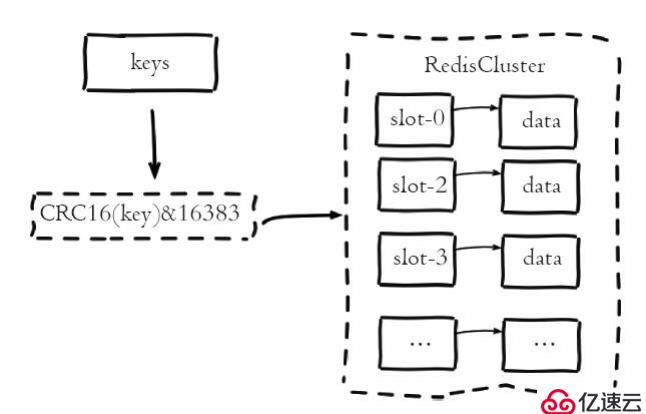
复述,集群采用虚拟槽分区,所有的键根据哈希函数映射到0 ~ 16383整数槽内,计算公式:槽=CRC16(关键),16383年。槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数据的槽,如下图所示:
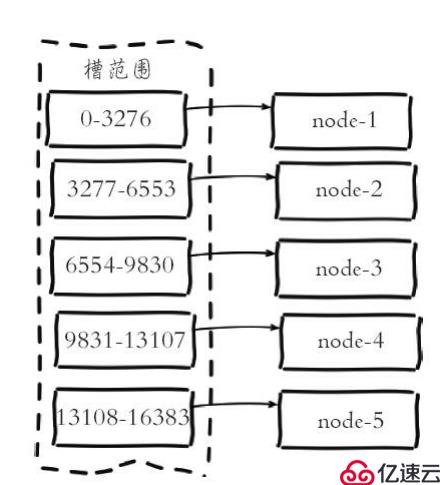
当集群有5个节点,每个节点平均大约负载3276个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到5个节点进行数据分区。每一个节点负责维护一部分槽以及槽所映射的键值数据,如下图所示:
复述,虚拟槽分区的特点:
解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
支持节点,槽,键之间的映射查询,用于数据路由,在线伸缩等场景。
数据分区是分布式存储的核心、理解和灵活运用数据分区规则对于掌握复述,集群非常有帮助。
集群功能限制
复述,集群相对单机的功能上存在一些限制,需要开发人页提前了解,在使用时做好规避。限制如下:
1)关键批量操作支持有限。如mset, mget,目前只支持具有相同槽值的关键执行批量操作。对于映射为不同槽值的键由于执行mget, mset等操作可能存在于多个节点上因此不被支持。
2)关键事务操作支持有限。同理只支持多关键在同一节点上的事务操作,当多个关键分布在不同的节点上时无法使用事务功能。
3)关键作为数据分区的最小粒度,因此不能将一个大的键值对象如散列表,列表等映射到不同的节点。
4)不支持多数据库空间。单机下的复述,可以支持16个数据库,集群模式下只能使用一个数据库空间,即db0。
5)复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
搭建集群
下面开始搭建集群工作,需要以下三个步骤:
1)准备节点
2)节点握手
3)分配槽
准备节点
节点规划,使用三台机器,第台机器上部署两个复述,实例,分别为一主一从。
复述,集群一般由多个节点组成,节点数据至少为6个才能保证组成完整高可用的集群。每个节点需要开启配置开发支持集群的是的,让复述,运行在集群模式下。建议为集群内所有节点统一目录,一般划分三个目录:配置,数据,日志,分别存放配置,数据和日志相关文件,把6个节点配置统一放在conf目录下,集群相关配置如下:
其他配置和单机模式一致即可,配置文件命名规则复述——{港口}。相依,准备好配置后启动所有节点,命令如下:
检查节点是日志是否正确,内容如下
redis_1上的6379节点启动成功,第一次启动时如果没有集群配置文件,它会自动创建一份,文件名称采用cluster-config-file参数项控制,建议采用节点——{港口}。参看格式定义,通过使用端口号区分不同节点,防止同一机器下多个节点彼此覆盖,造成集群信息异常。如果启动时存在集群配置文件,节点会使用配置文件内容初始化集群信息,启动过程如下图:




