介绍 Python可以做什么 # !,/usr/bin/env Python
#,_ * _ 编码:utf-8 _ * _
#作者:亚伦
,
得到lxml import etree
import csv
import 系统
,
主机=& # 39;& # 39;
title=& # 39; & # 39;
result_list=[],
def htm_parse (l):,,,,
if 才能;& # 39;# d43f3a& # 39;,拷贝etree.tostring (l):
,,,的信息=u"严重,安康;“+ l.text
elif 才能;& # 39;# ee9336& # 39;,拷贝etree.tostring (l):
,,,的信息=u"高危,安康;“+ l.text
elif 才能;& # 39;# fdc431& # 39;,拷贝etree.tostring (l):
,,,的信息=u"中危,安康;“+ l.text
elif 才能;& # 39;# 3 fae49& # 39;,拷贝etree.tostring (l):
,,,的信息=u"低危,安康;“+ l.text ,,,,,
elif 才能;& # 39;# 0071 b9 # 39;,拷贝etree.tostring (l):
,,,的信息=u # 39;信息泄露,安康;& # 39;+ l.text
其他的才能:
,,,的信息=& # 39;Parsing 错误,Check that 从而versions 断开连接;一致强生# 39;
return 才能;信息
def 主要(文件名):
时间=html 才能;etree.parse(文件名,etree.HTMLParser ())
ls 才能=html.xpath (& # 39;/html/身体/div [1]/div [3]/div,)
for 才能小姐:ls:拷贝
,,,if “字体大小:,22 px;,粗细:,大胆;,填充:,10 px 0;“,拷贝etree.tostring(我):
,,,,,主机=i.text
,,,elif “this.style.cursor",拷贝etree.tostring(我):
,,,,,结果=主机+“,安康;“+ htm_parse(我)
,,,,,print 结果
,,,,,result_list.append(结果)
return 才能;result_list
if __name__ ==, & # 39; __main__ # 39;:
文件名才能=sys.argv [1]
时间=list_host 才能;主要(文件名)
with 才能打开(& # 39;result.csv& # 39;, & # 39; wb # 39;), as f:
,,,f.write (u # 39; \ ufeff& # 39; .encode (& # 39; use utf8 # 39;))
,,,w =, csv.writer (f)
,,,w.writerow((& # 39;服务器ip # 39;, & # 39;漏洞级别& # 39;,& # 39;漏洞编号& # 39;,& # 39;漏洞名称& # 39;])
,,,for 小姐:拷贝list_host:
,,,,,data=https://www.yisu.com/zixun/i.split (' - ', 3)
w.writerow ([item.encode (use utf8)项数据])
这篇文章将为大家详细讲解有关如何利用Python半自动化生成Nessus报告,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
Python是一种编程语言,内置了许多有效的工具,Python几乎无所不能,该语言通俗易懂,容易入门,功能强大,在许多领域中都有广泛的应用,例如最热门的大数据分析,人工智能,网页开发等。
<强> 0 x01前言
Nessus是一个功能强大而又易于使用的远程安全扫描器,Nessus对个人用户是免费的,只需要在官方网站上填邮箱,立马就能收到注册号了,对应商业用户是收费的。当然,个人用户是有16个IP限制,通过企业邮箱可以体验免费7天的Nessus专业版,IP无限制。
<强> 0 x02 Nessus使用
登录后通过新的扫描创建扫描任务,扫描完成后,我们即可导出扫描报告.Nessus提供4种报告类型导出:
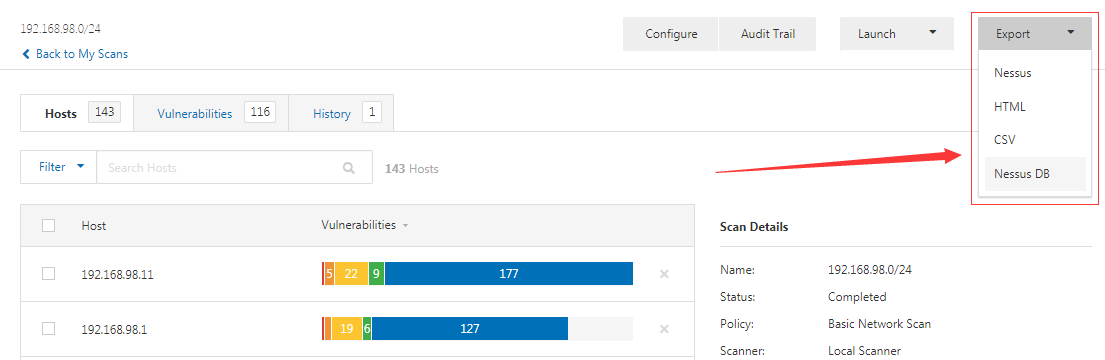
我们选择HTML类型,报告选择习俗,臀部的选择主机,导出HTML报告。
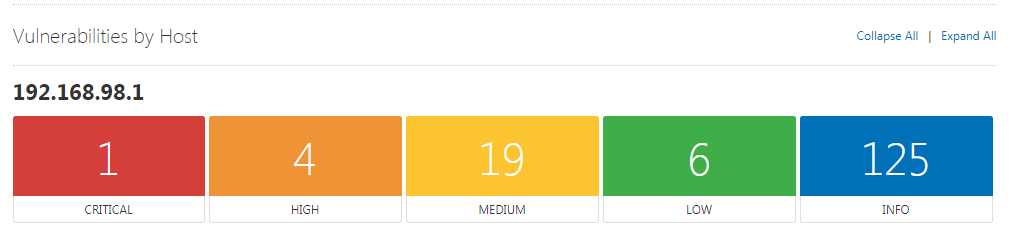
但这些报告还需要进一步整理成我们想要的格式,并且去掉不必要的消息,得到最终我们希望能够得到信息。
那首先我们确认一下,想要得到的信息是哪些呢?
1,服务器IP
2,漏洞危害级别
3,漏洞名称
这三个最基本的信息,对我来说就差不都足够了,我就知道哪些服务器存在高危漏洞,并提供解决漏洞修复建议。
<强> 0 x03 Python脚本
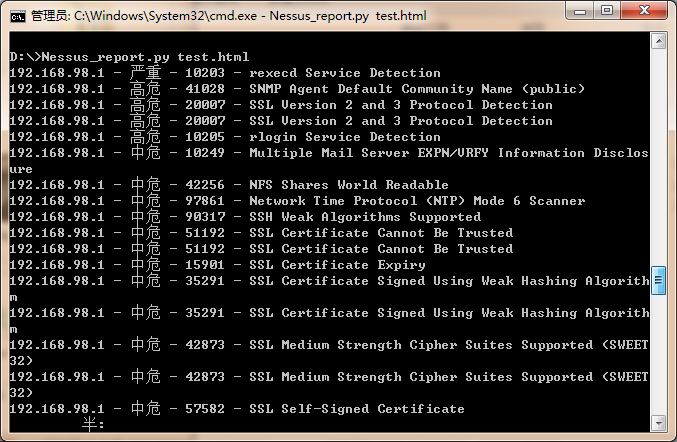
通过解析HTML文件,获取相关漏洞信息,并输出到csv文件。
脚本运行效果如下: