
介绍 Python的数据类型有哪些吗? import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
,
时间=df pd.read_csv (& # 39; train.csv& # 39;)
df.head ()
df。形状 <李> import pandas as pd
import matplotlib.pyplot as plt
,
#,Subsetting 从而数据集
11856 #,Index marks 从而最终获得of year 2013
时间=df pd.read_csv (& # 39; train.csv& # 39;,, nrows=11856)
,
#,Creating train 以及test 集
10392 #,Index marks 从而最终获得of October 2013
时间=train df (0:10392)
时间=test df (10392)
,
#,Aggregating 从而,dataset at daily 水平
df(& # 39;时间戳# 39;],=,pd.to_datetime (df (& # 39; datetime # 39;],,格式=& # 39;% d - % - % Y % H: %猴# 39;),#,4位年用Y, 2位年用Y
时间=df.index df(& # 39;时间戳# 39;】
时间=df df.resample (& # 39; d # 39;) .mean(), #按天采样,计算均值
,
火车[& # 39;时间戳# 39;],=,pd.to_datetime(火车[& # 39;datetime # 39;],,格式=& # 39;% d - % - % Y % H: %猴# 39;)
train.index =,火车[& # 39;时间戳# 39;】
时间=train train.resample (& # 39; d # 39;) .mean (), #
,
测试(& # 39;时间戳# 39;],=,pd.to_datetime(测试[& # 39;datetime # 39;],,格式=& # 39;% d - % - % Y % H: %猴# 39;)
时间=test.index 测试[& # 39;时间戳# 39;】
时间=test test.resample (& # 39; d # 39;) .mean ()
,
# Plotting 数据
train.Count.plot (figsize=(15、8),标题=,& # 39;Daily 客流量# 39;,,字形大?14)
test.Count.plot (figsize=(15、8),标题=,& # 39;Daily 客流量# 39;,,字形大?14)
plt.show () dd =, np.asarray(火车[& # 39;计数# 39;])
时间=y_hat test.copy ()
y_hat[& # 39;天真的# 39;],=,dd (len (dd),安康;1]
plt.figure (figsize=(12,, 8))
plt.plot (train.index,,火车[& # 39;计数# 39;],,标签=& # 39;火车# 39;)
plt.plot (test.index,测试[& # 39;计数# 39;],,标签=& # 39;测试# 39;)
plt.plot (y_hat.index, y_hat[& # 39;天真的# 39;],,标签=& # 39;Naive 预测# 39;)
plt.legend (loc=& # 39;最佳# 39;)
plt.title (“Naive Forecast")
plt.show ()
这篇文章主要介绍怎么用Python进行时间序列预测,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
python的数据类型:1。数字类型,包括int(整型),长(长整型)和浮子(浮点型)。2。字符串,分别是str类型和unicode类型。3。布尔型,Python布尔类型也是用于逻辑运算,有两个值:True(真)和虚假的(假)。4。列表,列表是Python中使用最频繁的数据类型,集合中可以放任何数据类型。5。元组,元组用“()”标识,内部元素用逗号隔开。6。字,字典典是一种键值对的集合。7。集合,集合是一个无序的,不重复的数据组合。
<强>数据准备
数据集(JetRail高铁的乘客数量)下载。
假设要解决一个时序问题:根据过往两年的数据(2012年8月至2014年8月),需要用这些数据预测接下来7个月的乘客数量。
依照上面的代码,我们获得了2012 - 2014年两年每个小时的乘客数量。为了解释每种方法的不同之处,以每天为单位构造和聚合了一个数据集。
从2012年8月- 2013年12月的数据中构造一个数据集。
<李>创建训练和测试文件用于建模。前14个月(2012年8月- 2013年10月)用作训练数据,后两个月(2013年11月- 2013年12月)用作测试数据。
<李>以每天为单位聚合数据集。
我们将数据可视化(训练数据和测试数据一起),从而得知在一段时间内数据是如何变化的。
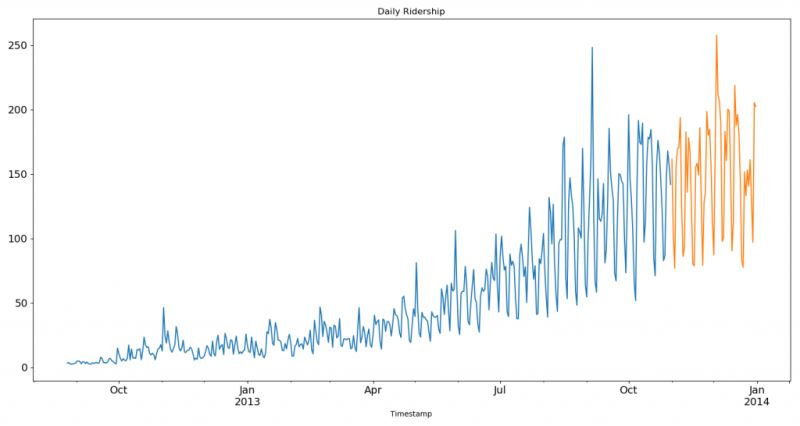
<强>方法1:朴素法
假设y轴表示物品的价格,x轴表示时间(天)
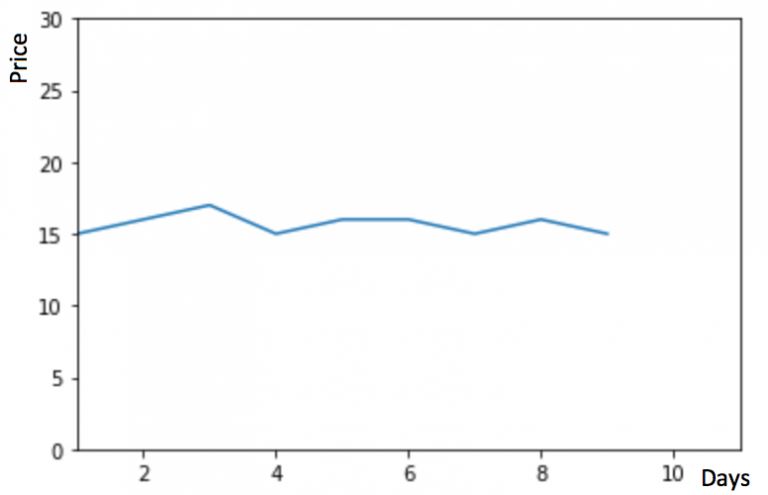
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法。即美元\帽子{y_ {t + 1}}=y_t $




