
大家都知道,复述,之所以性能好,读写快,是因为复述是一个内存数据库,它的操作都几乎基于内存。但是内存型数据库有一个很大的弊端,就是当数据库进程崩溃或系统重启的时候,如果内存数据不保存的话,里面的数据就会丢失不见了。这样的数据库并不是一个可靠的数据库。
所以数据的持久化是内存型数据库的重中之重。它不仅提供数据保存硬盘的功能,还可以借此用硬盘容量扩展数据存储空间,使得复述的可以存储超过机器本身内存大小的数据。
复述,对于数据持久化提供了两种持久化的方案,RDB与AOF。它们的原理和使用场景都大不相同,下面我们来详细地了解下。
RDB——数据快照(快照)
RDB、提供一个某个时间点的数据的快照,保存在RDB文件中。它可以通过<代码>保存/BGSAVE 命令手动执行,把数据写快照到RDB文件,也可以通过配置,定时执行。
复述,也可以通过加载RDB文件,把数据从磁盘加载读取到复述中。
RDB文件创建
连上复述,设值一些值,然后执行<代码> 保存命令。

然后可以查看下redis.conf的持久化工作目录。进入目录可以看到保存了一个垃圾场。rdb文件。该文件是一个二进制文件,无法直接正常打开。
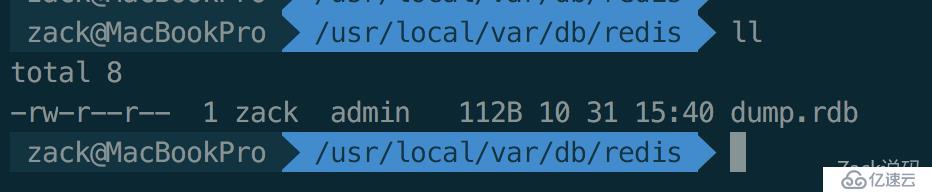
至于<代码>保存/BGSAVE>
注:复述是单进程的,所以<代码> BGSAVE>
以上是手动执行的过程。但在生产我们很少会手动登上服务去执行操作,所以更多的时候是依赖复述的配置,定时保存RDB文件。
打开<代码>复述。设计> 的快照配置,节省点的设置。
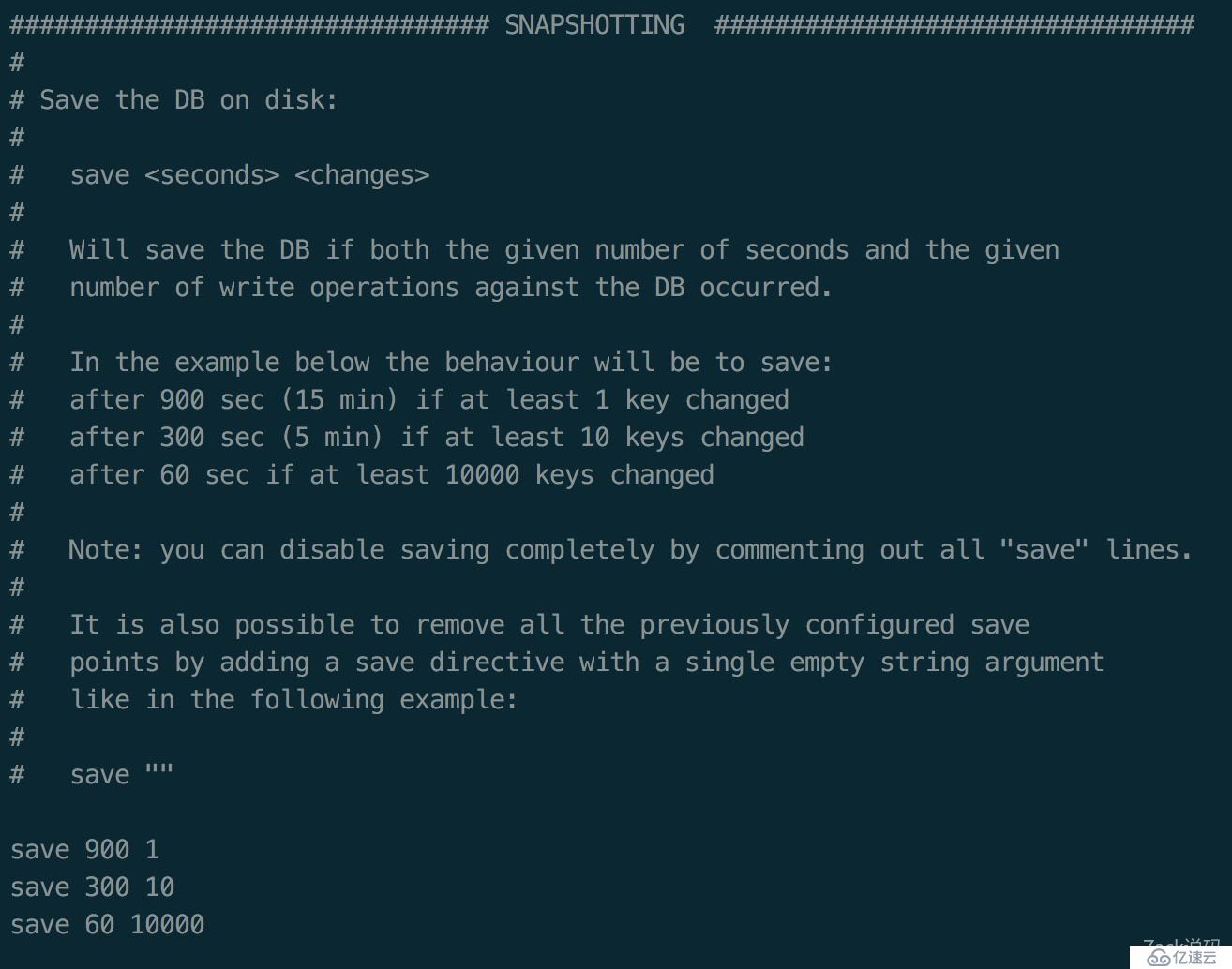
并且复述中,依然有之前设置的三个值。说明复述,在启动的时候,会加载数据初始化。
不过,这里加载的初始化数据不一定是RDB的。如果复述,开启了AOF,会优先从AOF初始化数据,否则才会加载RDB的数据。
RDB优缺点
优点:
-
<李> RDB是某一时间点的快照,是一个紧凑的单文件,更多用于数据备份。可以按每小时或每日来备份,方便从不同的版本恢复数据。
<李>单文件容易传输到远程服务做故障恢复。
<李> RDB可以叉子进程进行持久化,使复述,可以更好地处理用户请求李
<李>在大量数据的情况下,RDB相比较于AOF会更快的加载。
缺点:
-
<李>如果复述,不及时保存RDB文件,会造成数据的丢失。例如系统突然断电,但未来得及保存数据。即使你设置更多的保存点,也无法保证100%的数据不丢失。
<李> RDB经常需要叉子进程去执行,但如果再大量数据的情况下,这个叉操作会非常耗CPU资源的。对比AOF虽然也是叉,但是它的数据保存处理是可以控制的,不需要全量保存。
AOF——日志追加(扩展)
复述的另外一种持久化方案就是AOF,添加alt="进阶的复述,之数据持久化RDB与AOF”>
AOF和RDB是可以共存的,只要保存的文件名不冲突。
AOF fsync同步规则
配置文件往下拉,看到<代码> fsync> 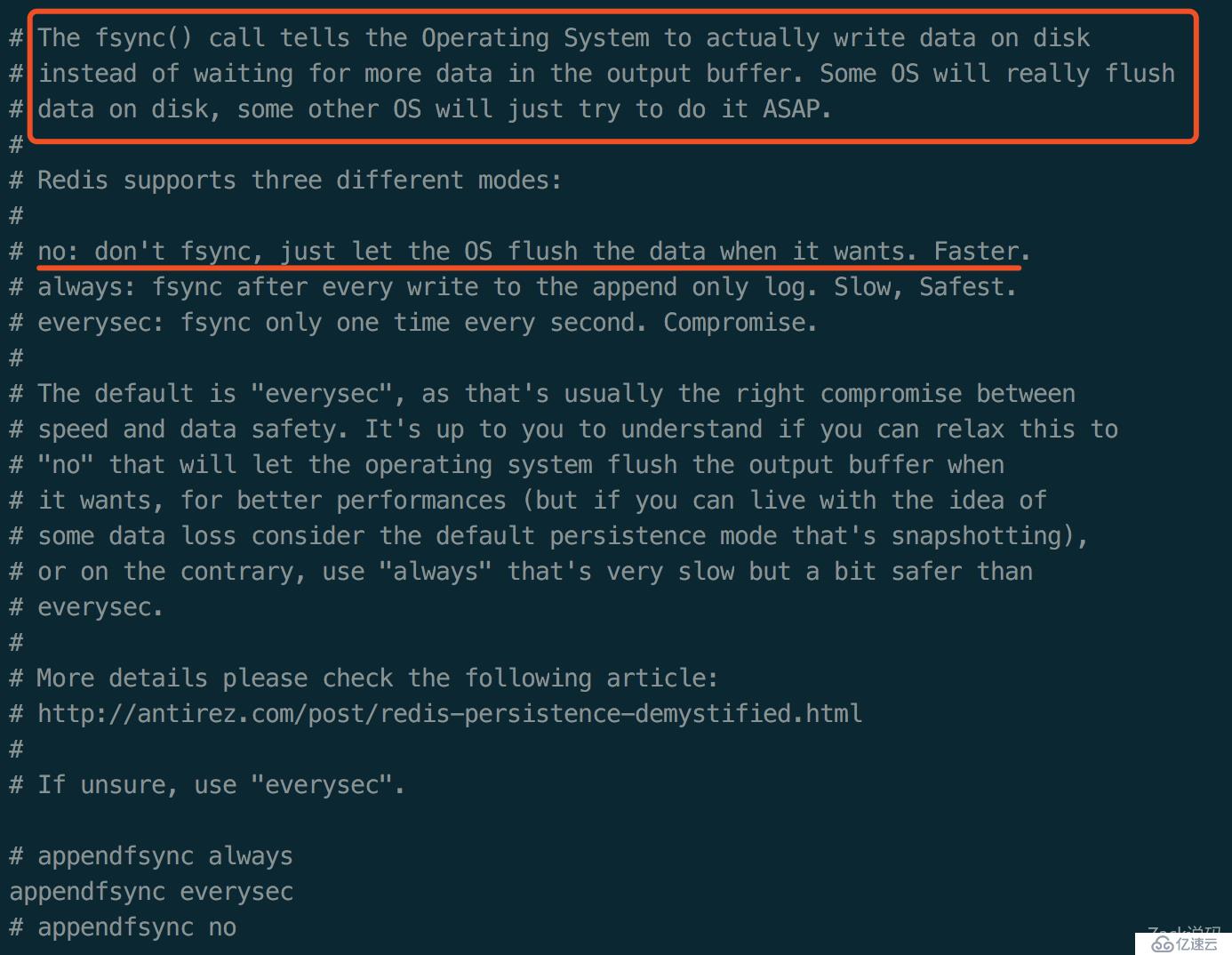 进阶的复述,之数据持久化RDB与AOF
进阶的复述,之数据持久化RDB与AOF




