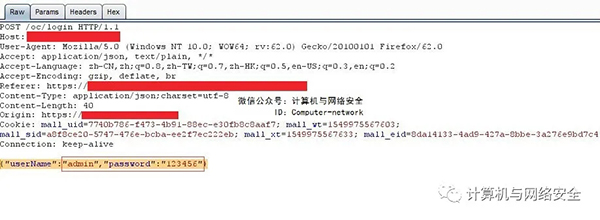
在前几天写的一篇文字中,我描述了一次失败的经历,对于很在乎过程的我,描述下来就是成功。然而,我不得不回退到DxR,研究一下它的本质而不是其算法思
想。之所以失败,是因为我的逆反心理在作的怪,我真的没有研究DxR的本质就开始动的手,无疑于打一场毫无准备且对对手完全不了解的恶仗,如果不适可而止,其
结果必然和当初死磕开一样悲惨!
DxR的本质
DxR并没有发明什么新的算法,它之所以高效是因为它分离了路由项中的<>强路由前缀和下一跳这两个基本元素。在这个的基础上,它就可以采用三张表来实现自己的既高效又占用空间小的目的。我来总结一下:
DxR算法的前提:分离了路由前缀和下一跳。
这
个前提及其重要!分离前缀和下一跳可以消除数据冗余,构建查找表的目标就从构建单纯的查找匹配表转换成了构建IPv4地址的某一段区间和下一跳表的映射关
系,这就直接导致了区间查找。我们来看一下很类似的Trie树查找算法,这个算法中路由前缀和下一跳是作为一个“路由项“绑定在一起的,因此查找的过程就
是一个精确匹配+回溯的过程。而DxR算法则消除了回溯的过程。
DxR算法的设施:直接索引表,区间表,下一跳表。
这个我后面还会说,但记住,这不是核心,这只是一种实现方式。
DxR算法表设计:直接索引表的意义
直接索引表合并了巨大的IPv4地址区间,以便区间表在合并后的少的多的区间中更快速地进行搜索,两个表的目的都是指向下一跳表的索引。这就建立了区间到下一跳的映射。
用路由前缀将IPv4地址空间分割成区间
如
果到此为止你还不知道DxR算法是什么,那也无所谓,其实它的思想很简单。路由表的最终结果就是将某个连续地址段对应到某个下一跳(不允许不连续掩码
了…),因此路由表实际上是将整个IPv4地址空间分割成了若干个区间,每个区间只和一个下一跳关联。我把那篇关于记录失败经历的文章中一个正确的图
贴如下:

拿
着目标IP地址当索引,向右走,碰到的第一个路由项就是结果。最长掩码的逻辑完全体现在插入/删除过程中,即从左到右前缀依次变短,长前缀的路由项会盖在
短前缀的路由项的前面,这就是核心思想。虽然我现在已经否定了拿IPv4地址直接去做索引,但是核心思想并没有变,即“拿XX映射到具体的下一跳”,在那
篇失败记录中,XX是IPv4地址索引,而在正确的做法中,XX是区间。其实在HiPac防火墙中,也正是使用了这个思想,即区间查找。在HiPac算法
中,区间就是匹配域,而下一跳对应的规则。
,,,,,,那么,DxR算法就是针对上述图示的一步步优化。为了更好的说明DxR,我再次给出上图的变换形式:
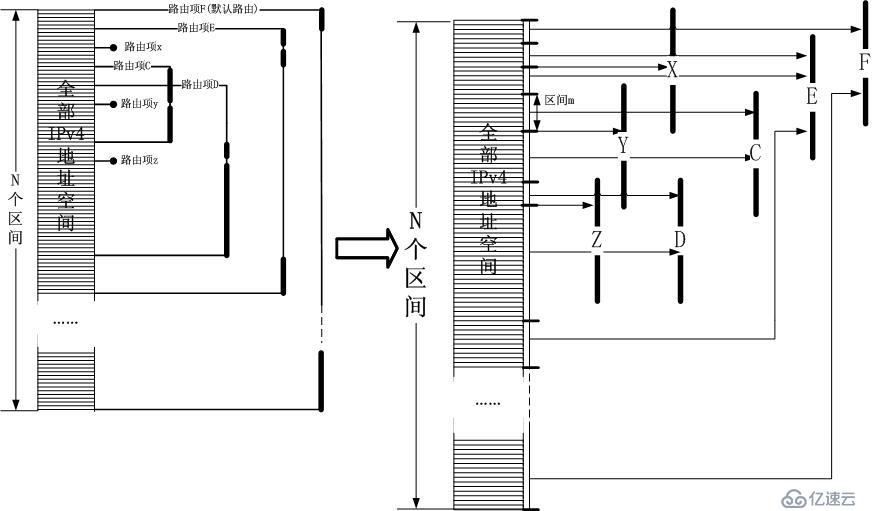
区间查找
如
果按照上面的图示,整个IPv4地址空间被分割成了N个区间,路由查找的最终目标是将某个IPv4地址对应到某个区间中!到此为止,其实工作已经完成了。
但是有个前提,那就是你要找出或者自己实现一个高性能的“区间匹配算法”!,即建立一个区间表,内部保存N个区间项,每个区间项对应一个下一跳索引,比如
C区间m对应下一跳,我们的目标是给定一个IPv4地址,判断它属于哪个区间。这样的算法比比皆是,自己实现一个似乎也不难,比如二分法,哈希算法等,所
以本文不关注这些。然而DxR似乎并不满足这个发现,当然我也不满足.DxR似乎希望找到一种更加优化的方式实现这个区间匹配。
,,,,,,在给出DxR的框架之前,到此为止,我们发现,DxR实质上就是使用了区间匹配来将一个目标IPv4地址对应到一个区间,然后取出该区间对应的下一跳!
划分子区间
如 果针对每一个到来数据包的目标IPv4地址都要在N个区间中做匹配,似乎不太优雅。如果能将这N个区间划分为若干个子区间,那么每次匹配时匹配的区间数量 将会大大减少,比如N为100,如果能将整个IPv4地址空间划分为20个相等的子区间,那么每次匹配的区间数量将会是5个,而不是100个! !但是这里 又有一个前提,那就是划分子区间的开销一定要能被由于减少区间数量而带来的收益抵消掉,并且收益要更大。