
电竞大数据时代,数据对比赛的观赏性和专业性都起到了至关重要的作用。同样的,这也对电竞数据的丰富性与实时性提出了越来越高的要求。

电竞数据的丰富性从受众角度来看,可分为赛事,战队和玩家数据,从游戏角度来看,维度可由英雄,战斗,道具以及技能等组成;电竞数据的实时性包括赛前两支战队的历史交战记录,赛中的实时比分,胜率预测,赛后比赛分析和英雄对比等。
<>强如果你想了解大数据的学习路线,想学习大数据知识以及需要免费的学习资料可以加群:784789432。欢迎你的加入。每天下午三点开直播分享基础知识,晚上20:00都会开直播给大家分享大数据项目实战。
如果你还是认为写博客浪费时间,请参考大卫罗宾逊撰写的相关文
因此多维度的数据支持,结核病到PB级别的海量数据存储与实时分析都对底层系统的架构设计有着更高的要求,亦带来了更严峻的挑战。
本文将介绍电竞数据平台FunData架构演进中的设计思路及相关技术,包括×××处理方案,结构化存储转非结构化存储方案和数据API服务设计等。在其v1.0 beta版本中,FunData为顶级MOBA类游戏DOTA2(由阀公司出品)提供了相关的数据接口。
<强> 1.0架构
项目发展初期,依照MVP理论(最小化可行产品),我们迅速推出FunData的第一版系统(架构图如图1)。系统主要有两个模块:主人与奴隶。
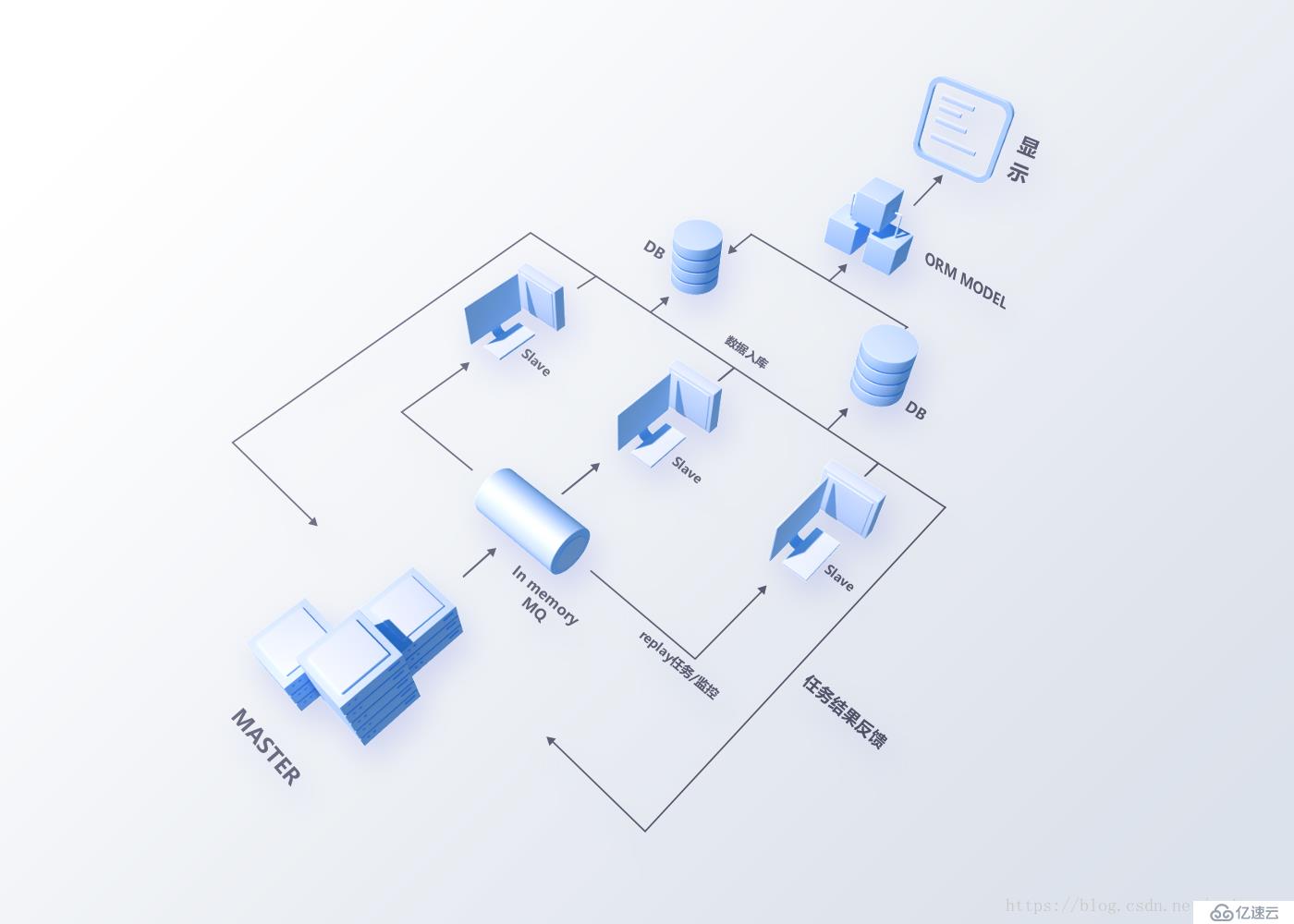
1.0图1 etl架构图
主模块功能如下:
定时调用蒸汽接口获取比赛ID与基础信息;
通过内存的消息队列分发比赛分析任务到奴隶节点;
记录比赛分析进度,并探测各奴隶节点状态。
奴隶模块功能如下:
监听队列消息并获取任务,任务主要为录像分析,录像分析参考GitHub项目清晰与外套;
分析数据入库。
系统上线初期运行相对稳定,各维度的数据都可快速拉取。然而随着数据量的增多,数据与系统的可维护性问题却日益突出:
新增数据字段需要重新构建DB索引,数据表行数过亿构建时间太长且造成长时间锁表;
系统耦合度高,不易于维护,主节点的更新重启后,奴隶无重连机制需要全部重启;同时内存消息队列有丢消息的风险;
系统可扩展性低,奴隶节点扩容时需要频繁的制作虚拟机镜像,配置无统一管理,维护成本高;
DB为主从模式且存储空间有限,导致数据API层需要定制逻辑来分库读取数据做聚合分析;
节点粒度大,奴隶可能承载的多个分析任务,故障时影响面大。
在开始2.0架构设计与改造前,我们尝试使用冷存储方法,通过迁移数据的方式来减轻系统压力(架构设计如图2所示)。由于数据表数据量太大,并发多个数据迁移任务需要大量时间,清理数据的过程同样会触发重新构建索引,方案的上线并没有根本性地解决问题。
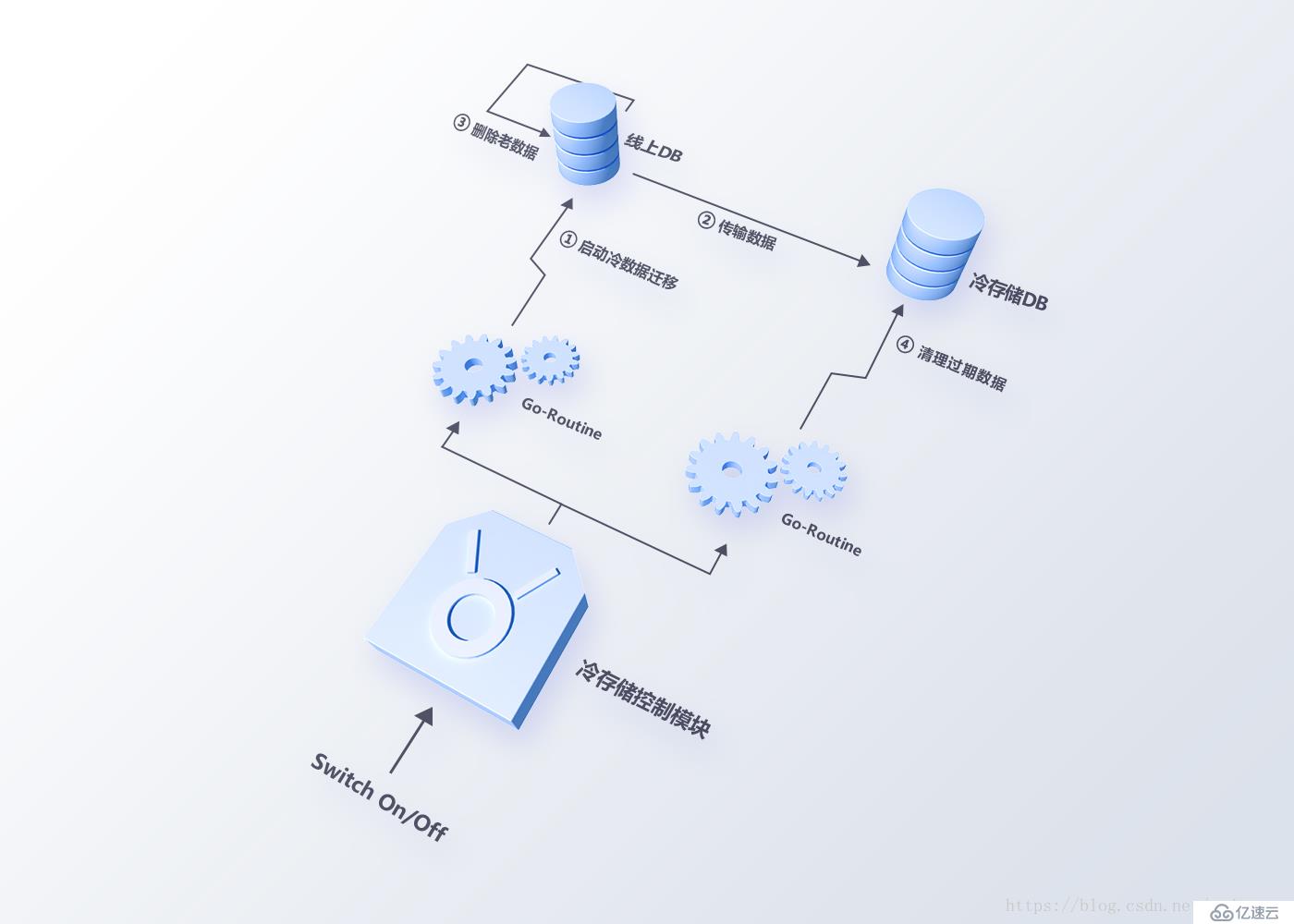
图2冷存储方案
<强> 2.0架构
吸取1.0系统的经验,在2.0架构设计(架构图如图3)中,我们从维护性,扩展性和稳定性三个方面来考虑新数据系统架构应该具备的基本特性:
数据处理任务粒度细化,且支持高并发处理(全球一天DOTA2比赛的场次在120年万场,录像分析相对耗时,串行处理会导致任务堆积严重),
数据分布式存储;
系统解耦,各节点可优雅重启与更新。
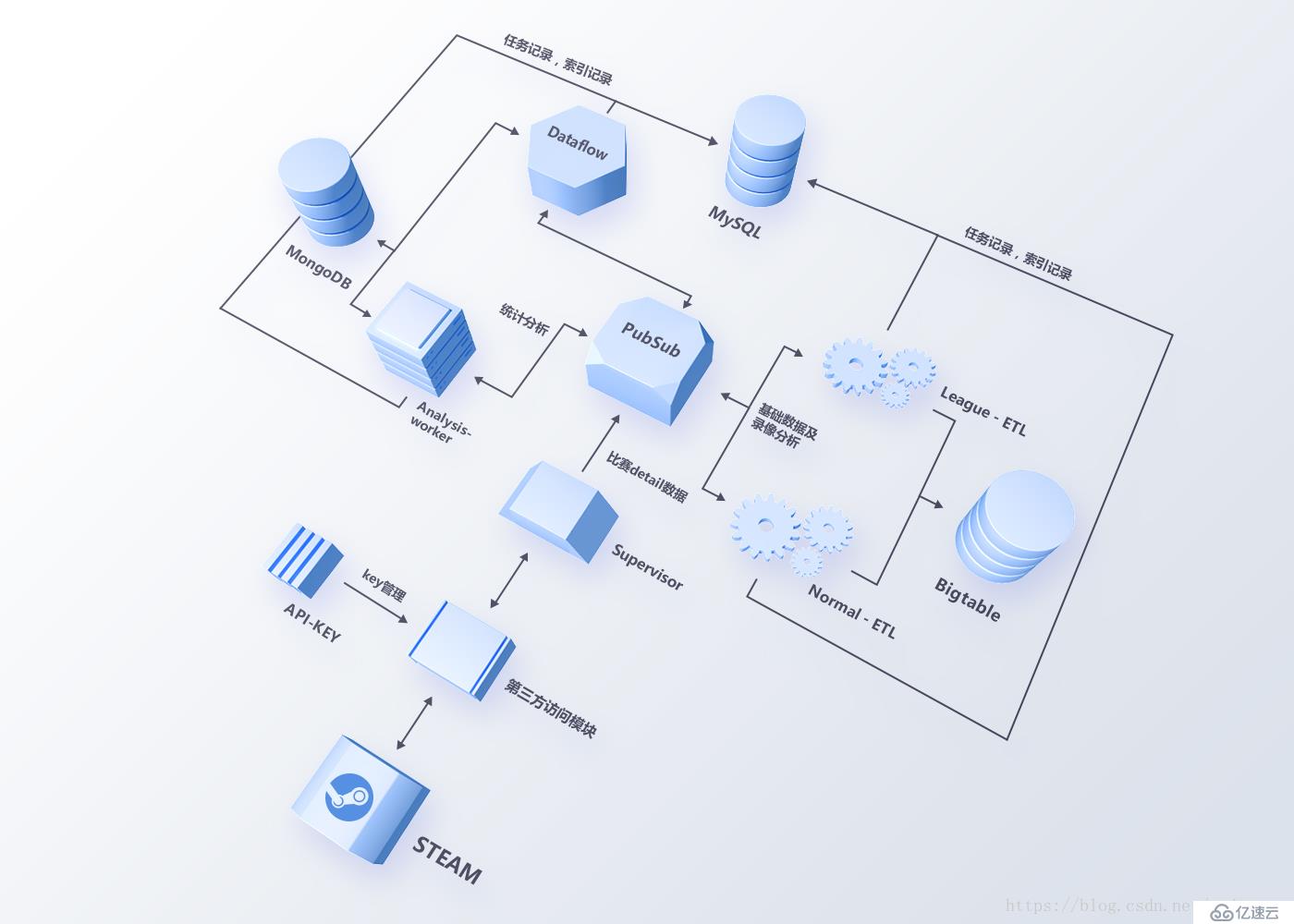
2.0图3 ETL总架构图
2.0系统选择谷歌云平台来构建整个数据ETL系统,利用PubSub(类似卡夫卡)作为消息总线,任务被细化成多个话题进行监听,由不同的工人进行处理。这样一方面减少了不同任务的耦合度,防止一个任务处理异常导致其他任务中断,另一方面,任务基于消息总线传递,不同的数据任务扩展性变得更好,性能不足时可快速横向扩展。
任务粒度细化
从任务粒度上看(如图3所示),数据处理分为基础数据处理与高阶数据处理两部分。基础数据,即比赛的详情信息(KDA,伤害与补刀等数据)和录像分析数据(罗山击杀数据,伤害类型与英雄分路热力图等数据)由主管获取蒸汽数据触发,经过工人的清理后存入Google Bigtable;高阶数据,即多维度的统计数据(如英雄,道具和团战等数据),在录像分析后触发,并通过GCP的数据流和自建的分析节点(工人)聚合,最终存入MongoDB与Google Bigtable。




