
【报表查询性能】
1。数据量大或并发多导致的查询性能低下,BI界面拖拽响应很慢
通过集算器编写更为简单高效的算法加速计算进程,提升查询性能
<李>采用集算器可控存储和索引机制,为BI(立方体)提供高速的数据存储
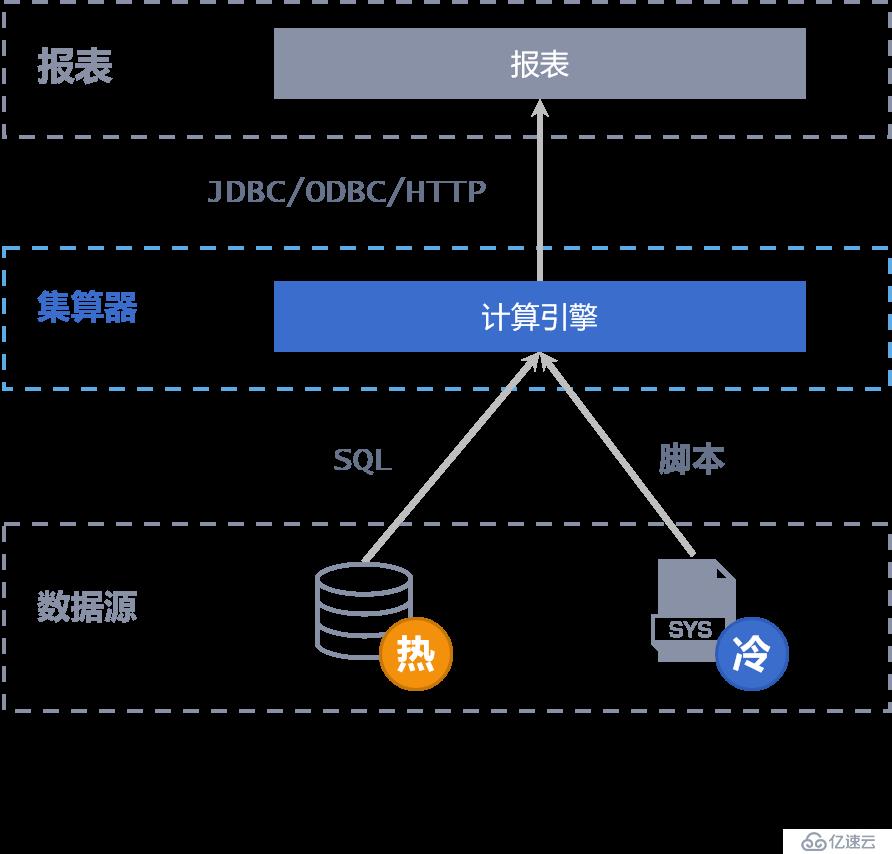
2。T + 0实时全量查询报表涉及数据量大,影响生产系统运行,而分库后又难以实施跨库混合运算
将冷热数据分离,仅将当期热数据存放在数据库中,冷数据存储在文件系统或数据库中,通过集算器完成跨源(库)计算,完成多源数据汇总,复杂计算,实现T + 0全量数据实时查询
<李>集算器提供不同数据库的基本SQL翻译功能,数据分库(同构异构均可)后,仍然可以使用通用SQL进行跨库查询
3。数据关联运算太多,十几甚至几十个表连接、性能恶劣
集算器重新定义关联运算,可以根据计算特征选用不同且高效的关联算法提升多表关联性能
<李>一对多的主外键表可采用指针式连接提高性能
<李>一对一的同维表和多对一的主子表可采用有序归并提升性能
4。数据源SQL复杂,嵌套层次多,数据库优化路径不可控,运算性能低
集算器采用过程计算,分步实施计算简化实现代码,无需嵌套
<李>过程中可以复用中间结果,性能更高
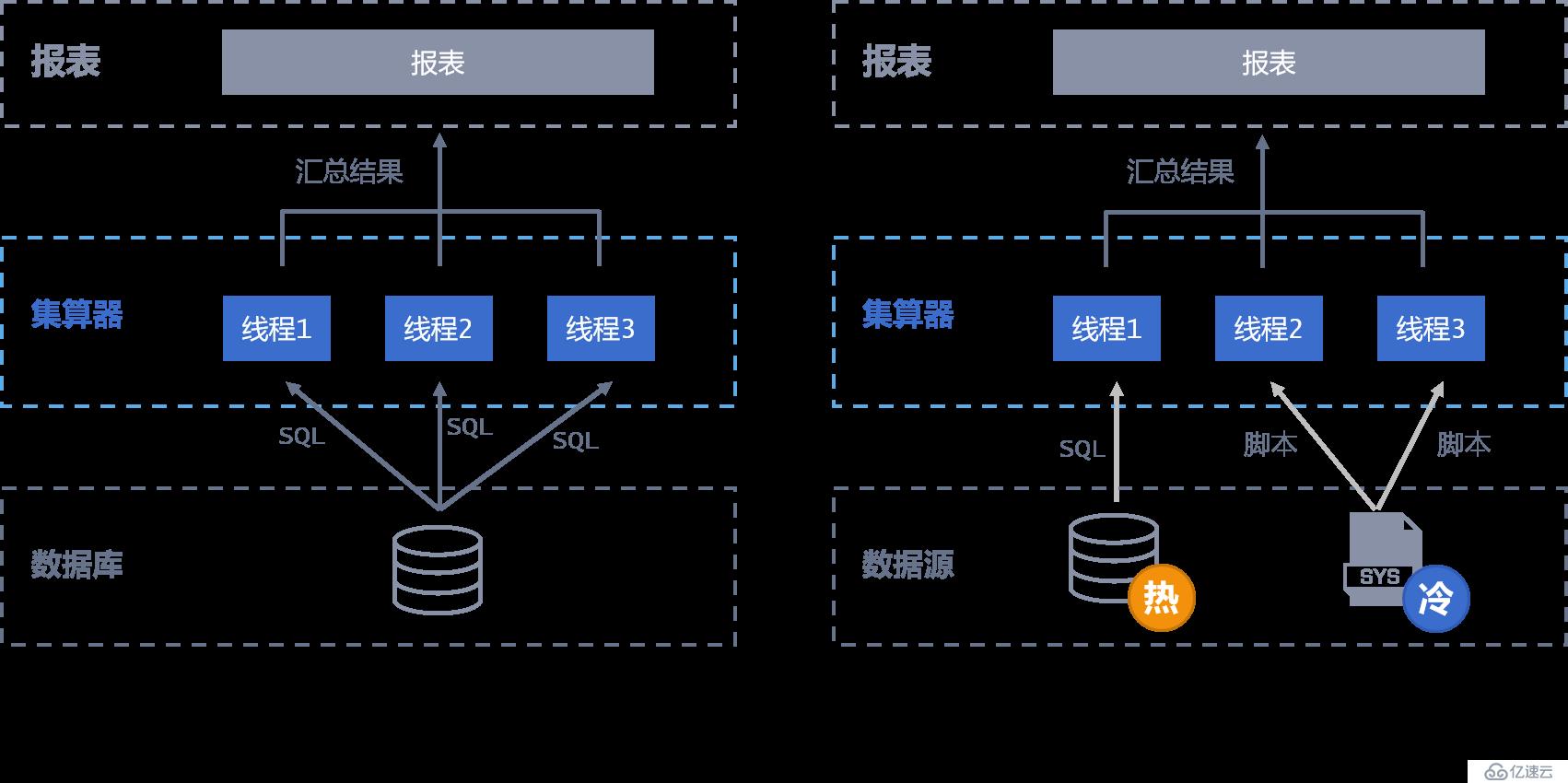
5。报表从数据库中取数量大,JDBC传输性能低
集算器通过(多线程)并行计算与数据库建立多个连接并行取数提升取数性能
<李>可将量大的冷数据事先存储在库外文件系统中,集算器基于文件直接查询计算,避免通过JDBC取数
6。清单式大报表难以及时呈现,采用数据库分页方式翻页效率很差
集算器将计算和呈现做成两个异步线程,取数线程发出SQL将数据缓存到本地交给呈现线程快速展现报表,此外取数线程只涉及一个事务不会出现数据不一致,保证数据准确性
【报表查询开发】
7。报表开发没完没了,占用程序员的过多工作量,找不到低成本高效率的应对手段
集算器帮助报表开发彻底工具化,不仅报表呈现层工具化,报表数据计算层也工具化,从而降低报表开发难度,报表实现更快更简单
<李>对人员要求更低,无需专业程序员
<李>报表业务不稳定导致报表没完没了不可能消灭,集算器提供了最低成本的应对
8。业务人员取数需求多,敏捷BI并不管,用技术部门应对这些需求费时费力
集算器作为完备计算引擎,支持过程计算开发快捷
<李>算法实现简单,适合一般技术人员使用
<李>提供可视化编程环境,即装即用使用简单
<李>通过多源支持,基于Excel/TxT/DB直接计算无需入库
9。数据源SQL或存储过程过于复杂,嵌套或步骤多,调试开发都很困难
集算器通过过程计算,分步编程简化算法开发难度,算法短小,分步同时降低了维护难度,极大改善上千行SQL编写调试和维护困难的情况
10。SQL(存储过程)语法涉及数据库方言,难以移植
集算器作为库外通用计算引擎,可以编写不依赖数据库的通用算法,数据库发生变化时无需更改核心算法,易于移植
11。复杂过程运算用SQL很难写,需要大量外部Java计算,开发效率低
集算器提供了完备的结构化数据计算能力,解决了Java集合运算困难的问题,无需再用Java编写
<李>集算器还很方便集成到现有应用中,与应用完美结合
12。Java和SQL编写的数据源与报表模板分开存储,程序耦合性太强,还难以做到热切换
集算器可作为报表独立的计算,层数据准备算法和报表模板一起存储,共同管理,可与应用分开部署,降低应用的耦合度




