今天我们来看下算法复杂度和效率的问题,在判断一个算法的效率时,操作数量中的常数项和其他次要项常常是可以忽略的,只需要关注<强> 强就能得出结论。那么我们如何用符号定性的判断算法的效率呢?算法的复杂度分为两部分:1,<强> 强,即;2,<强> 强,即。
数据结构重点关注的是算法的效率问题,因此,我们后面会集中于讨论算法的时间复杂度;但其使用的方法完全可以用于空间复杂度的判断!我们经常在进行算法的时间复杂度用<强> 来进行分析。下来对此种方法进行说明,算法效率严重依赖于操作(操作)数量,操作数量的估算可以作为时间复杂度的估算;在判断时首先关注操作数量的最高次项。如下:
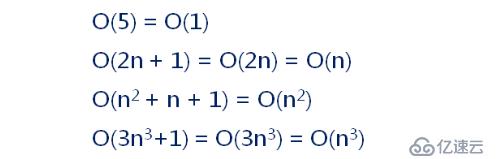
下来我们来分析下常见的时间复杂度:
1, <强> 强。如下:

2, <强> 强。如下

3 <强> 强。如下:

下来我们来看看常见的时间复杂度,如下图所示
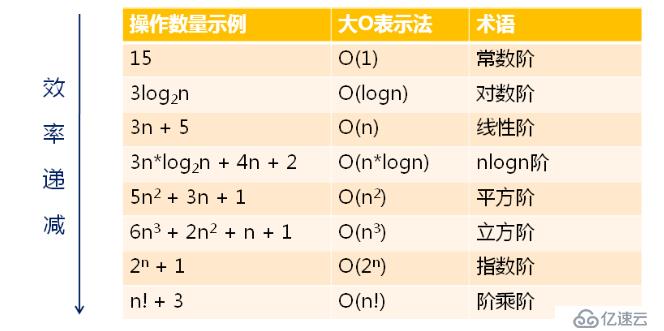
常见的时间复杂度的比较,如下

下面我们通过实例来进行分析下、下面的函数程序复杂度是怎样的
我们如果定义的数组[5]={1,2,3,4,5};如果是int min=发现(一个5 1);这种则是最好情况了,仅需执行1次循环,此时便是O(1),如果是int max=发现(一个5 5);此时便是最坏的情况了,需要全部执行,此时便是O (n)。那么此时算法的最好与最坏情况便体现出来了,当算法在最乖情况下仍然能满足需求时,可以推断,算法的最好情况和平均情况都满足需求。在以后没有进行特殊说明时,所分析算法的时间复杂度都是指最坏时间复杂度。
算法的空间复杂度(空间复杂性),其定义为S (n)=(f (n))。其中n为算法的问题规模,f (n)为空间使用函数,与n相关,例如,当算法所需要的空间是常数时,其空间复杂度为(1)。我么来看看下面这个程序的空间复杂度为多少
我们看到第一行为1,第三行的ret定义也为1,指针数组数组的定义其空间复杂度为n,下面两个进行了循环的空间复杂度分别为1。因此整个程序所需的单位内存为:n + 4,即空间复杂度:S (n + 4)=(n)那么时间跟空间之间是否存在某种联系呢?在多数情况下,算法的时间复杂度更令人关注,因为现在的内存都很大。如果有必要的话,下。来我们来看个空间换时间的示例代码,代码的背景是在1 - 1000中的某些数字搜组成的数组中,设计一个算法类找出出现次数最多的数字。
我们来看看打印结果