如果最小二乘线性回归算法最小化到回归直线的竖直距离(即,平行于y轴方向),则戴明回归最小化到回归直线的总距离(即,垂直于回归直线)。其最小化x值和y值两个方向的误差,具体的对比图如下图。
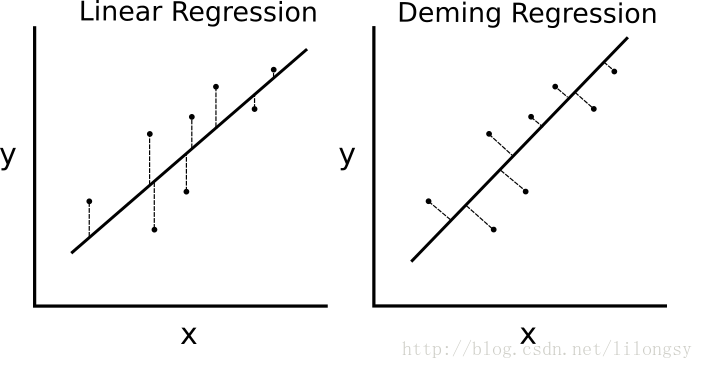
#戴明回归
#----------------------------------
#
#这个函数显示了如何使用TensorFlow
#解决线性戴明回归。
# y=Ax + b
#
#我们将使用虹膜数据,特别是:
# y=花萼长度
# x=花瓣宽度
进口matplotlib。pyplot作为plt
进口numpy np
进口tensorflow特遣部队
从sklearn导入数据集
从tensorflow.python.framework进口操作
ops.reset_default_graph ()
#创建图
税=tf.Session ()
#加载数据
#虹膜。data=[(花萼长度,萼片宽,花瓣长度,花瓣宽度))
虹膜=datasets.load_iris ()
x_vals=np。阵列([x [3] x iris.data))
y_vals=np。数组([y y iris.data] [0])
#申报批大小
batch_size=50
#初始化占位符
x_data=特遣部队。占位符(=[没有,1],形状dtype=tf.float32)
y_target=特遣部队。占位符(=[没有,1],形状dtype=tf.float32)
#创建变量线性回归
一个=tf.Variable (tf.random_normal(形状=[1]))
b=tf.Variable (tf.random_normal(形状=[1]))
#申报模式操作
model_output=tf.add (tf。matmul (x_data), b)
#宣布Demming损失函数
demming_numerator=tf.abs (tf。减去(y_target tf.add (tf。matmul (x_data), b)))
demming_denominator=tf.sqrt (tf.add (tf.square (A), 1))
损失=tf.reduce_mean (tf。truediv (demming_numerator demming_denominator))
#宣布优化器
my_opt=tf.train.GradientDescentOptimizer (0.1)
train_step=my_opt.minimize(亏损)
#初始化变量
init=tf.global_variables_initializer ()
sess.run (init)
#循环培训
loss_vec=[]
因为我在范围(250):
rand_index=np.random.choice (len (x_vals),大?batch_size)
rand_x=np.transpose ([x_vals [rand_index]])
rand_y=np.transpose ([y_vals [rand_index]])
sess.run (train_step feed_dict={x_data: rand_x y_target: rand_y})
temp_loss=sess.run(损失,feed_dict={x_data: rand_x y_target: rand_y})
loss_vec.append (temp_loss)
如果(i + 1) % 50==0:
打印(“步”+ str (i + 1) +“=? str (sess.run (A)) + " b=' + str (sess.run (b)))
print('='损失+ str (temp_loss))
#得到最优系数
(斜率)=sess.run (A)
[y_intercept]=sess.run (b)
#最适合线
best_fit=[]
因为我在x_vals:
我+ y_intercept best_fit.append斜率(*)
#阴谋的结果
plt。情节(x_vals y_vals、“o”标签=笆荨?
plt。情节(x_vals best_fit, r -,标签=最适合线,线宽=3)
plt。传奇(loc=白笊稀?
plt。标题(“花萼长度与踏板宽度”)
plt。包含(踏板宽度)
plt。ylabel(花萼长度)
plt.show ()
随着时间的推移#地块损失
plt。情节(loss_vec“k -”)
plt。标题(“每一代L2损失”)
plt.xlabel(代)
plt。ylabel (L2损失)
plt.show ()
结果:
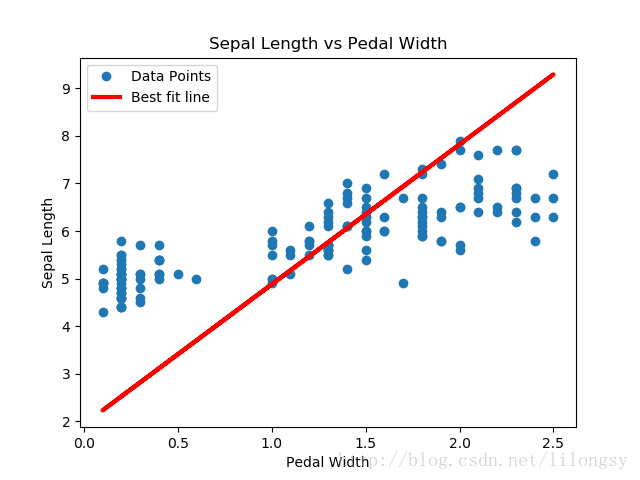 用TensorFlow实现戴明回归算法的示例
用TensorFlow实现戴明回归算法的示例





