上一篇内容,已经学会了使用简单的语句对网页进行抓取。接下来,详细看下urlopen的两个重要参数url和数据,学习如何发送数据数据

url不仅可以是一个字符串,例如:http://www.baidu.com.url也可以是一个请求对象,这就需要我们先定义一个请求对象,然后将这个请求对象作为urlopen的参数使用,方法如下:
同样,运行这段代码同样可以得到网页信息。可以看一下这段代码和上个笔记中代码的不同,对比一下就明白了。
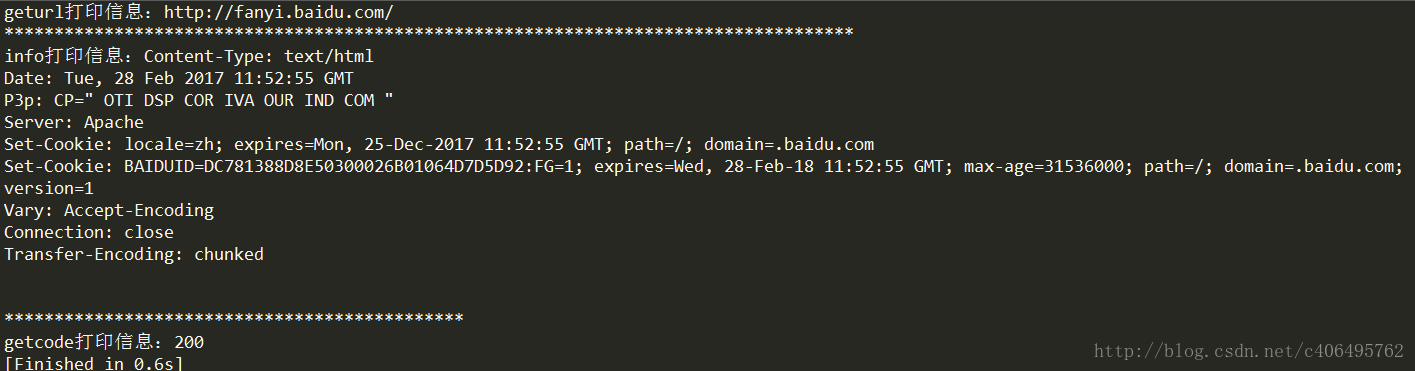
urlopen()返回的对象,可以使用读()进行读取,同样也可以使用geturl()方法,信息()方法,getcode()方法。

geturl()返回的是一个url的字符串;
info()返回的是一些元标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功。
关于元标签和HTTP状态码的内容可以自行百度百科,里面有很详细的介绍。
了解到这些,我们就可以进行新一轮的测试,新建文件名urllib_test04.py,编写如下代码:
可以得到如下运行结果:
我们可以使用数据参数,向服务器发送数据,根据HTTP规范,得到用于信息获取,后是向服务器提交数据的一种请求,再换句话说:
从客户端向服务器提交数据使用职位;
从服务器获得数据到客户端使用得到(获得也可以提交,暂不考虑)。
如果没有设置urlopen()函数的数据参数,HTTP请求采用得到的方式,也就是我们从服务器获取信息,如果我们设置数据参数,HTTP请求采用发布方式,也就是我们向服务器传递数据。
数据参数有自己的格式,它是一个基于应用程序/x-www.form-urlencoded的格式,具体格式我们不用了解,因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
向有道翻译发送数据,得到翻译结果。
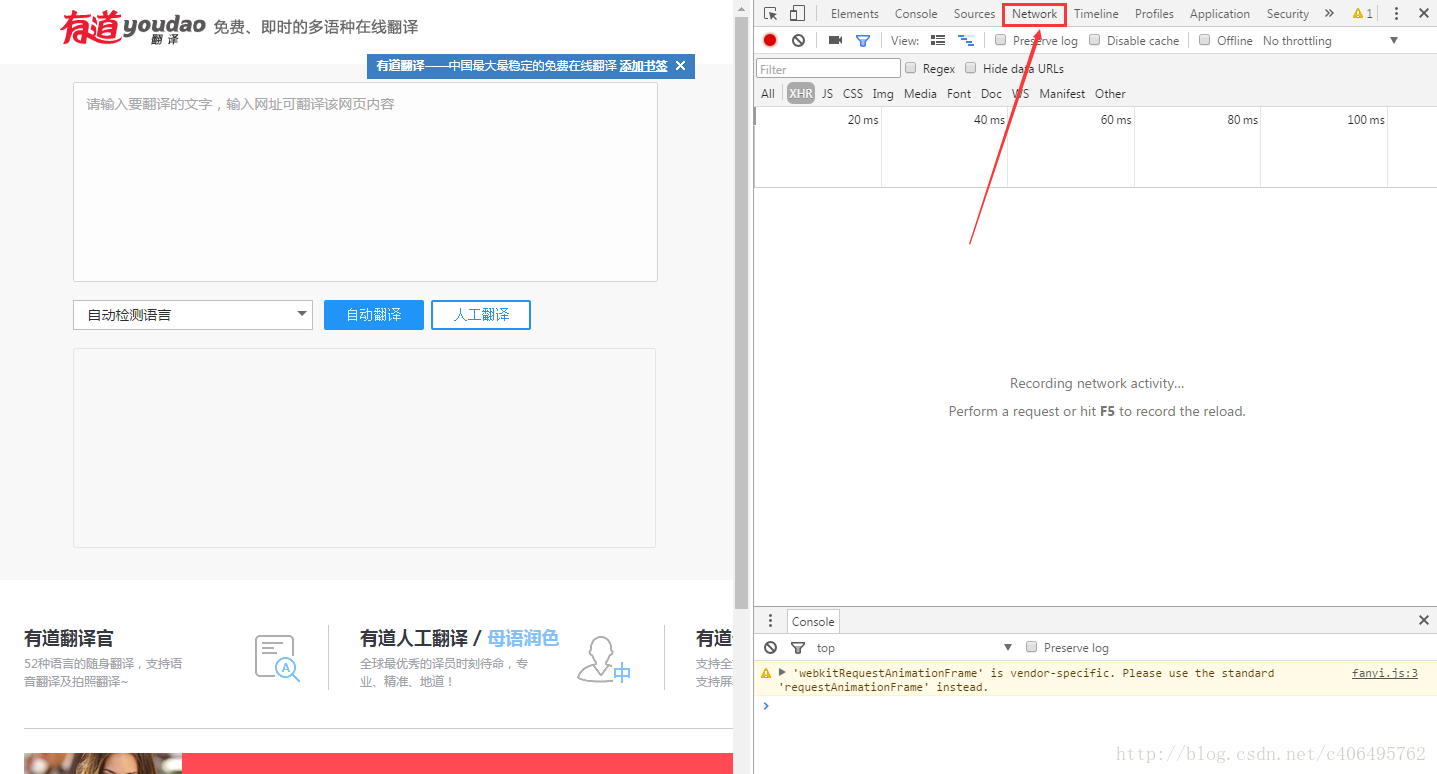
1。打开有道翻译界面,如下图所示:
2。鼠标右键检查,也就是审查元素,如下图所示:
3。选择右侧出现的网络,如下图所示: