
在熊猫里,DataFrame是最经常用的数据结构,这里总结生成和添加数据的方法:
①,把其他格式的数据整理到DataFrame中;
②在已有的DataFrame中插入N列或者N行。
假如我们在做实验的时候得到的数据是dict类型,为了方便之后的数据统计和计算,我们想把它转换为DataFrame,存在很多写法,这里简单介绍常用的几种:
<强>方法一:直接使用<代码> pd.DataFrame (data=https://www.yisu.com/zixun/test_dict) 即可,括号中的<代码> data=https://www.yisu.com/zixun/>
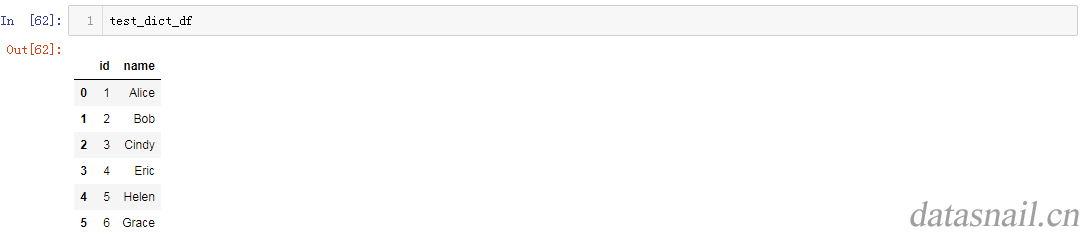
那么,我们就得到了一个DataFrame,如下: 应该就是这个样子了。 <强>方法二:使用<代码> from_dict 方法: 结果是一样的,不再重复贴图。 其他方法:如果你的dict变量很小,例如<代码> {“id”: 1、“名称”:“爱丽丝”}>
这样是不行的,会报错<代码> ValueError:如果使用所有的标量值,您必须通过一个索引>
后面的可以写多个<代码> pd.Index(范围(3)>
关于选择列,有些时候我们只需要选择dict中部分的键当做DataFrame的列,那么我们可以使用列参数,例如我们只选择“id”、“名称”列: 这里就不在多写了,后续变更颜色添加内容。 我们实验的时候数据一般比较大,而csv文件是文本格式的数据,占用更少的存储,所以一般数据来源是csv文件,从csv文件中如何构建DataFrame呢? txt文件一般也能用这种方法。 方法一:最常用的应该就是<代码> pd.read_csv (filename.csv)> 指定数据的分割方式,默认的是<代码>”、“ 如果csv中没有表头,就要加入<代码> 头参数 加入我们已经有了一个DataFrame,如下图: <强> 3.1添加列 此时我们又有一门新的物理课,我们需要为每个人添加这门课的分数,按照指数的顺序,我们可以使用插入方法,如下: 此时,就得到了添加好的DataFrame,需要注意的是DataFrame默认不允许添加重复的列,但是在插入函数中有参数<代码> allow_duplicates=True>
<强> 3.2添加行

熊猫DataFrame创建方法的方式




