
什么是MongoDB复制集?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
<强>一,蒙戈复制集简介
近年来,随着大数据越来越火,非关系型数据库的重要性被越来越多的人所认知,越来越多的开发者逐渐加入到NoSQL的阵营中。我们知不道NoSQL是alt="什么是MongoDB复制集">
MongoDB是支持数据复制的,它在复制集方面的优势与其他数据复制集一样,它通过将数据部署在多个不同的服务器上,防止因单机故障而造成数据的丢失,借助数据冗余来提高数据的可靠性和安全性,而且还可以通过复制技术构建分布式数据库,提高系统的访问性能和安全性。
MongoDB的复制集模式是主从复制。在所有的数据库服务的机器中,只有一台机器担当主要角色,其余的机器均是次要的。担当主要角色的机器接收所有来自客户端的写(写)操作请求,并完成该操作,从而保证了数据的一致性。担当主要角色的机器还能够把来自客户端的读(读)操作分配给其他机器(次要的),减轻主数据库服务器的压力。
<强>二、复制集创建和配置
1。如果之前开了蒙戈的服务,那么首先要结束掉蒙戈的服务
2。删除掉之前的星展银行和日志
3。在三台机器上分别配置dbs和日志(这里使用一台设备模拟三台设备做复制集,所以在一台设备上创建了三个数据库地址以及日志存放路径。)

4。启动三个实例,并且申明属于同一个复制集
①,首先要切换到mongodb目录下,在执行下面的命令。
②,启动三个实例
——dbpath:指定数据库路径
——logpath:指定日志存放路径
——叉:后台运行
——端口:设置启动的端口
——replSet:设置同一个复制集,复制集的名称自定义
——杂志:32 linux需要这个参数才能启动,64位不需要这个参数
——smallfiles:启动时占用较小的空间,如果空间不是很缺少,一般不需要这个参数
-storageEngine:设置数据库的引擎,由于不支持wiredTiger引擎,需要切换支持的引擎,64位系统不需要切换引擎。

三个数据实例启动成功截图:

③,查看三个实例启动成功。

5,配置复制集文件,并初始化复制集
①,首先进入任意一个实例的mongo客户端命令模式
②,切换到管理

③,定义变量
查看变量是否生成打印变量名称: printjson(rsconf)
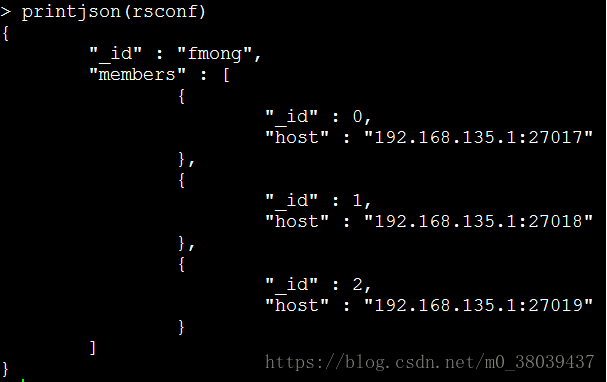
④、根据上面的配置做初始化:rs.initiate(rsconf)
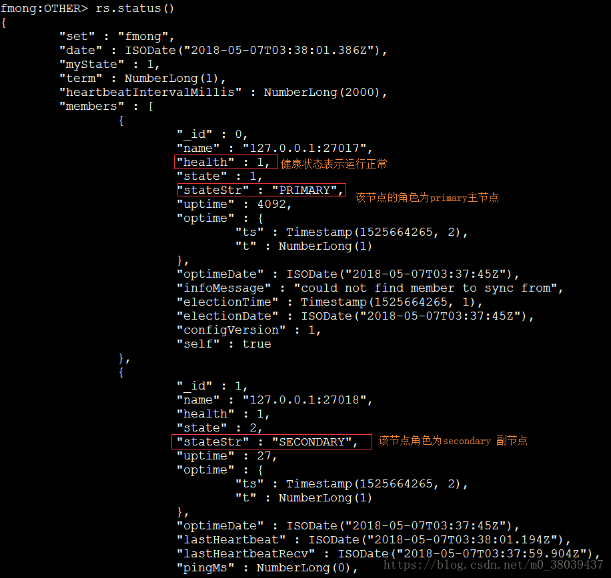
⑤、查看初始化成功后,各个节点的状态:rs.status()
6、节点的增加与删除操作
①、删除节点:rs.remove('子节点的host:port')
②、查看删除节点后的复制集节点状态:rs.status()
③、增加节点:rs.add('子节点的host:port')(注意:使用增加节点命令添加的host必须是上面配置复制集变量包含的host在内的才可以添加,如果没有包含的host是添加不进去的。如果想添加没有包含的host需要修改复制集变量,才可以添加。)




