卡夫卡作为一个流式数据平台,对开发者提供了三种客户端:生产者/消费者,连接器,流处理。本文着重分析这三种客户端的线程模型。看到最后的通常都有惊喜。
消费者的线程模型
0.8版本以前的消费者客户端会创建一个基于ZK的消费者连接器,一个消费者客户端是一个Java进程,消费者可以订阅多个主题,每个主题也可以多个线程。为了让消息在多个节点被分布式地消费,提高消息处理的吞吐量,卡夫卡允许多个消费者订阅同一个主题,这些消费者需要满足”一个分区只能被一个消费者中的一个线程处理”的限制条件。通常,我们会将同一份相同业务处理逻辑的应用程序部署在不同机器上,并且指定一个消费组编号。当不同机器上的消费者进程启动后,所有这些消费者进程就组成了一个逻辑意义上的消费组。
消费组中的消费者数量是动态变化的,当有新消费者加入消费组,或者旧消费者离开消费组,都会触发基于ZK的消费组”再平衡”操作。当“再平衡”操作发生时,每个消费者都会在客户端执行分区分配算法,然后从全局的分配结果中获取属于自己的分区。它的缺点是消费者会和ZK产生频繁的交互,造成ZK集群的压力过大,并且容易产生羊群效应和脑裂等问题。
0.8版在本以后,卡夫卡重新设计了客户端,并且引入了“协调者”和“消费组管理协议”。新的消费者将“消费组管理协议”和“分区分配策略”进行了分离。协调者负责消费组的管理,而分区分配则会在消费组的一个主消费者中完成。采用这种方式,每个消费者都需要发送下面两种请求给协调者。
加入组请求:协调者收集消费组的所有消费者,并选举一个主消费者执行分区分配工作。
同步组请求:主消费者完成分区分配,由协调者将分区的分配结果传播给每个消费者。
新版本的消费者客户端引入了一个客户端协调者的抽象类,它的实现除了消费者的协调者,还有一个连接器的实现。
连接器的线程模型
卡夫卡连接器的出现标准化了卡夫卡与各种外部存储系统的数据同步。用户开发和使用连接器就变得非常简单,只需要在配置文件中定义连接器,就可以将外部系统的数据导入卡夫卡或将卡夫卡数据导出到外部系统。如图1所示,中间部分都是卡夫卡连接器的内部组件,包括源连接器(源连接器)和目标连接器(水槽连接器)。
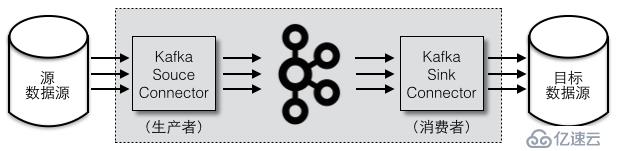
图1卡夫卡连接器的源连接器与目标连接器
卡夫卡连接器的单机模式会在一个进程内启动一个工人以及所有的连接器和任务。分布式模式的每个进程都有一个工人,而连接器和任务则分别运行在各个节点上。图2列举了连接器和任务在不同工人上的四种分布方式:
一个工人,一个源任务,一个目标任务
一个工人,两个源任务,两个目标任务
两个工人,两个源任务,两个目标任务
三个工人,两个源任务,两个目标任务
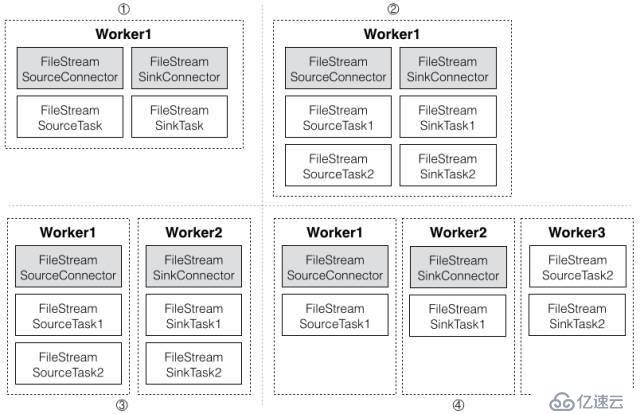
图2分布式模式的卡夫卡连接器集群
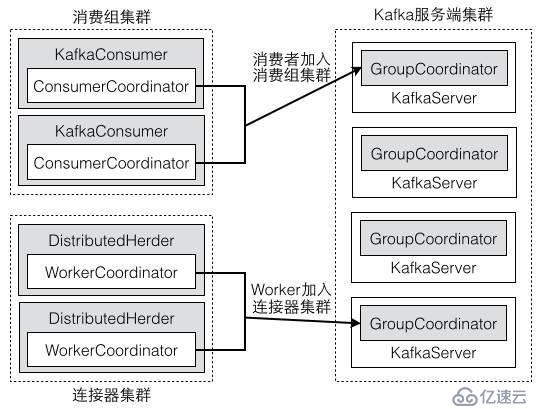
分布式模式下,不同工人进程之间的协调工作类似于消费者的协调。消费者通过协调者获取分配的分区,工人也会通过协调者获取分配的连接器与任务。如图3所示,消费者客户端和工人客户端为了加入到组管理中,分别通过客户端的协调者对象来和服务端的消费组协调(GroupCoordinator)通信。